对第 i 个样本,输入xi,模型输出分数向量 s=f(xi;W)∈RC,其中 si 是第 i 类的分数。直觉上,预测准确则loss低,预测错误则loss高。
损失函数最常见的两种选择有Hinge loss和Softmax loss。
P1:Hinge loss
多分类 SVM 希望:正确类的分数 syi 比每个错误类分数 sj 至少高一个固定间隔(margin)Δ。
对单个样本的 loss 定义为:
Li=j=yi∑max(0,sj−syi+Δ)
若 syi≥sj+Δ,这一项为 0(该错误类“达标了”)
若 syi<sj+Δ,就按“差多少”线性惩罚
在二分类里经常把标签写成 y∈{−1,+1},预测打分为 t(例如 t=wTx),hinge loss 常写成:
ℓ(t,y)=max(0,1−yt)
直观对应关系:分类正确且“置信度/间隔”足够大(yt≥1)→ loss=0;分类错或置信度不够(yt<1)→ 线性惩罚
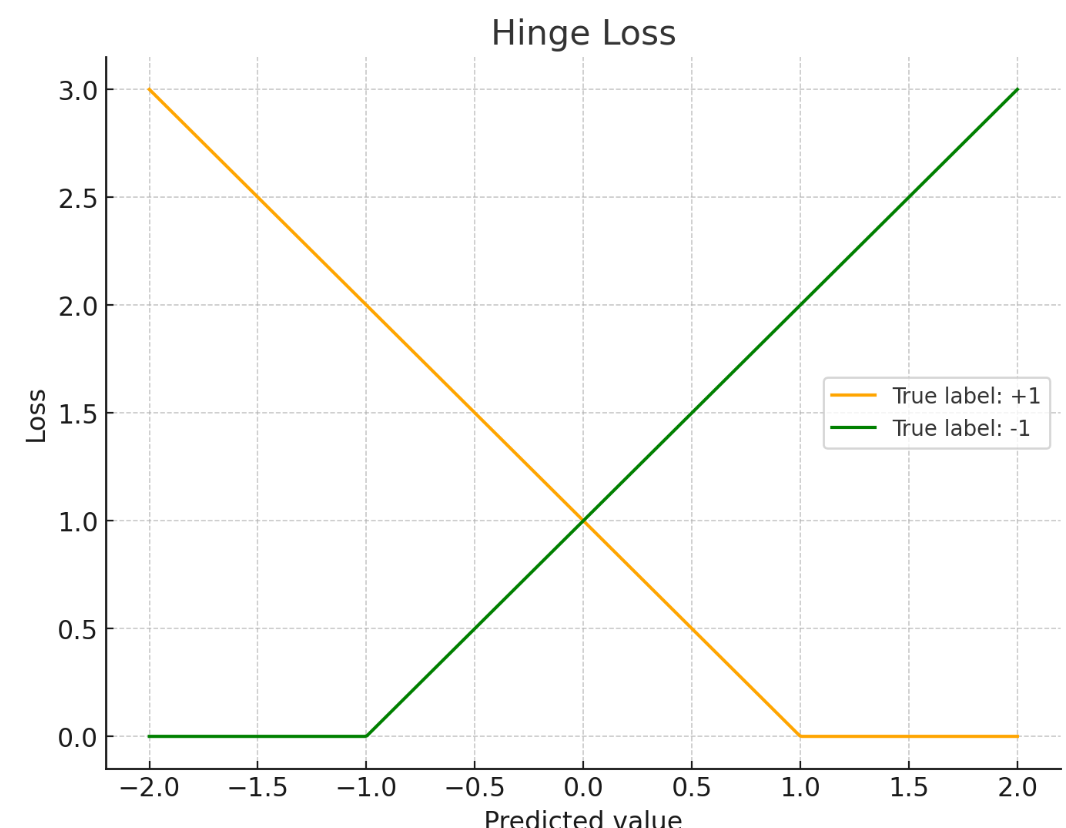
一些实现里还会用squaredHinge=max(0,1−yt)2,对违反margin的样本惩罚更重。
P2:Softmax loss
Softmax把分数当作未归一化的对数概率(logits),并得到类别概率:
pj=∑keskesj

直观来看是这样:先使用指数将得到的分数全部变为正数,再归一化为概率分布。将交叉熵作为损失,将softmax代入L=−logP即可得到第i项的损失函数。
Li=−log(∑jesjesyi)=−syi+logj∑esj
softmax 里有指数,esj 可能非常大导致溢出。常用的稳定技巧:
s←s−jmaxsj
因为对所有分数加同一个常数不会改变 softmax 的结果(分子分母同乘一个常数会约掉),但能显著提升数值稳定性。
P3:Hinge vs Softmax
两者在实践中都很常见,效果通常接近,但优化“性格”不同:
- Hinge / SVM 更“局部”:只关心是否超过 margin;一旦满足就不再推动分数继续分离
- Softmax 更“全局”:永远不会完全满意,总想让正确类概率更大、错误类更小
一个对比:
对于分数 [10,−100,−100] 和 [10,9,9],只要 margin 满足,SVM 可能都给 0 loss;Softmax 会认为 [10,9,9] “不够自信”,因为错误类也很接近,会产生更大 loss。
P4:信息论补充——熵和交叉熵
之前没有学过信息论,故让ai写了这部分,还是蛮清晰的。
自信息(Surprisal)与编码长度
信息论把一个事件 x 发生时携带的信息量定义为自信息:
I(x)=−logp(x)
它可以理解为:如果你用概率 p(x) 来做无损编码,那么事件越罕见(p(x) 越小),所需编码长度越长。
备注:对数底为 2 时单位是 bit;用自然对数时单位是 nat。深度学习里默认用自然对数更常见。
熵(Entropy)= 最小平均编码长度
若随机变量服从真实分布 P,熵定义为“平均意义下的最小编码长度”(香农的核心观点):
H(P)=Ex∼P[−logP(x)]=−x∑P(x)logP(x)
直觉:分布越“平均”(不确定性越大),熵越大;若几乎总发生同一件事,熵就很小。
交叉熵(Cross-Entropy)= 用 Q 去编码来自 P 的数据
现实里我们通常不知道真实分布 P,模型给出一个估计分布 Q。
如果你用 Q 来编码来自 P 的样本,平均编码长度就是交叉熵:
H(P,Q)=Ex∼P[−logQ(x)]=−x∑P(x)logQ(x)
交叉熵与熵的关键关系:
H(P,Q)=H(P)+DKL(P∥Q)≥H(P)
因为 KL 散度 DKL≥0,所以用“错误的分布” Q 编码,平均长度只会更长;只有当 Q=P 时才达到最短。
为什么 Softmax loss 就是交叉熵
分类任务里,标签通常是 one-hot:真实分布 P 把全部概率质量放在正确类别 y 上(P(y)=1,其余为 0)。
这时:
- H(P)=0(因为它完全确定)
- 交叉熵退化为
H(P,Q)=−logQ(y)
而 Q(y) 正是 softmax 输出的正确类概率 py,因此 Softmax 的交叉熵损失就是:
Li=−logpyi
二分类交叉熵(BCE)常用形式
若二分类标签 y∈{0,1},模型预测正类概率为 p,则
BCE(y,p)=−[ylogp+(1−y)log(1−p)]
它同样是“真实分布(由标签给出)”与“模型分布”的交叉熵。
P5:最小化负对数似然——L=-logP的另一种理解
课上直接写 L=−logP。当时没看懂,在《Understanding Deep Learning》里找到一段对数似然的证明:
假设数据独立同分布,训练集的条件似然可写成乘积
Pr(y1,…,yI∣x1,…,xI)=i=1∏IPr(yi∣xi)
于是最大似然准则是最大化联合概率(似然):
ϕ^=argϕmaxi=1∏IPr(yi∣f(xi,ϕ))
为避免小概率连乘带来的数值下溢问题,对似然取对数;由于 log 单调递增,最优点不变:
ϕ^=argϕmaxlogi=1∏IPr(yi∣f(xi,ϕ))=argϕmaxi=1∑IlogPr(yi∣f(xi,ϕ))
把“最大化似然”改写成“最小化损失”,就得到负对数似然:
ϕ^=argϕmin[−i=1∑IlogPr(yi∣f(xi,ϕ))]≡argϕminL(ϕ)
当使用softmax时,Pr(yi∣f(xi,ϕ)) 就是正确类的softmax概率。








