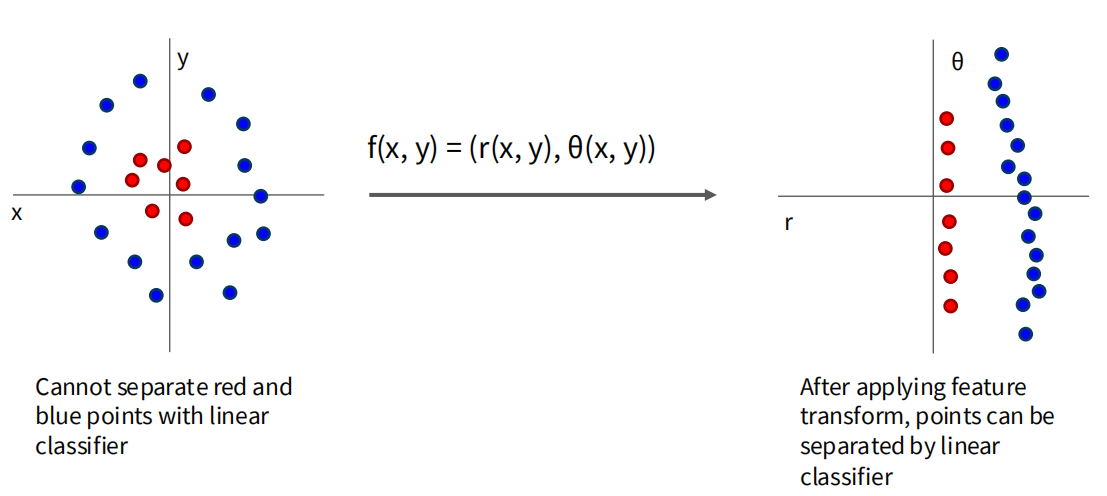神经网络
此前已经使用 f = W x f = Wx f = W x
显然,如左图所示,一个线性分类器并不能很好的拟合分布复杂的数据,但是如果线性分类前将数据的分布转化成容易被线性分类器分类的形式(如右图所示),那么线性分类器也能取得不错的效果。神经网络的目标就是通过多层非线性变换,将数据映射到一个新的空间,使得在该空间中数据更容易被区分开来。
在原有基础上再加一层线性变换和非线性激活函数,得到:
f = W 2 max ( 0 , W 1 x ) f = W_2 \max(0, W_1 x)
f = W 2 max ( 0 , W 1 x )
其中 m a x ( 0 , t ) max(0, t) ma x ( 0 , t ) f = ( W 2 W 1 ) x = W x f = (W_2 W_1) x = W x f = ( W 2 W 1 ) x = W x
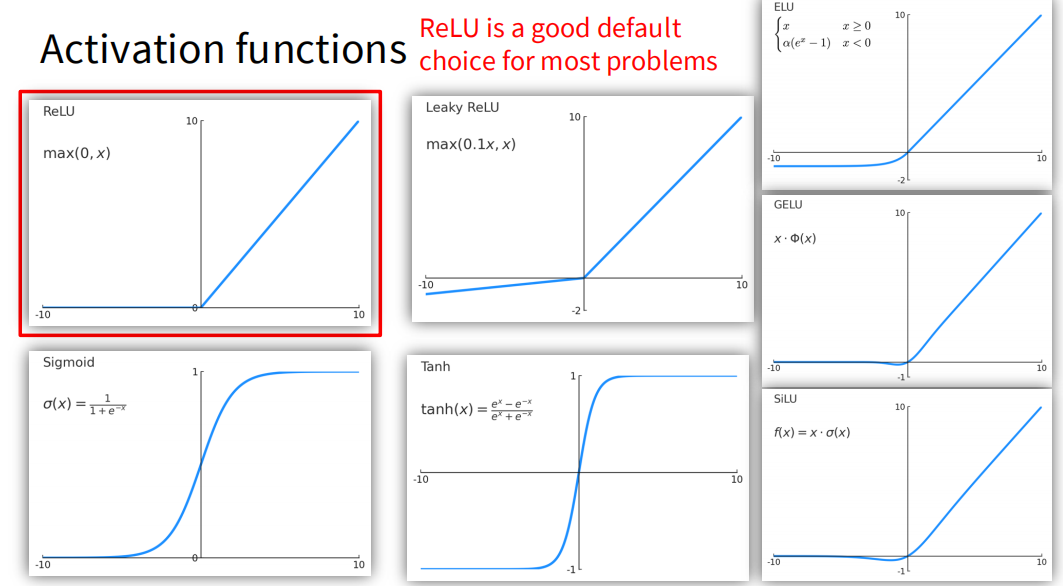
激活函数有很多常见的形式,如 Sigmoid、Tanh、ReLU 等。ReLU 函数在实践中表现良好,且计算简单,因此被广泛使用。ReLU 函数的导数在正区间为 1,在负区间为 0,这使得它在反向传播过程中计算效率较高。激活函数一般根据具体任务和数据分布选择,不同的激活函数可能会对模型的性能产生一定影响。
两层神经网络的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import numpy as npfrom numpy.random import randnN, D_in, H, D_out = 64 , 1000 , 100 , 10 x, y = randn(N, D_in), randn(N, D_out) w1, w2 = randn(D_in, H), randn(H, D_out) for t in range (2000 ): h = 1 / (1 + np.exp(-x.dot(w1))) y_pred = h.dot(w2) loss = np.square(y_pred - y).sum () print (t, loss) grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h.T.dot(grad_y_pred) grad_h = grad_y_pred.dot(w2.T) grad_w1 = x.T.dot(grad_h * h * (1 - h)) w1 -= 1e-4 * grad_w1 w2 -= 1e-4 * grad_w2
如图所示,随着神经网络的层数增加,模型的表达能力也随之增强,能够更好地拟合复杂的数据分布。然而,过深的网络也可能导致过拟合和梯度破碎等问题,因此在设计神经网络时需要合理选择层数和结构。
反向传播
反向传播是训练神经网络时最核心的计算机制:前向传播负责把输入变成 loss,反向传播负责把这个 loss 对每个参数的影响计算出来。它并不是一种新的求导规则,而是链式法则在计算图上的系统化应用。理解反向传播时可以先从标量计算图入手,再推广到矩阵运算和整层网络。
在无矩阵运算的情境下理解
梯度下降通过损失函数对参数的梯度来调整参数,从而最小化损失函数。反向传播则用来计算神经网络中损失函数对各层参数的梯度。反向传播的核心思想是利用链式法则,将复杂函数的导数分解为多个简单函数导数的乘积,从而高效地计算梯度。
用“计算图”来理解反向传播:前向传播时,每个节点只负责根据输入计算输出;反向传播时,每个节点接收来自后续节点的上游梯度,再乘上自己这个局部函数的导数,把梯度分发给自己的输入。这样整个网络不需要一次性写出一个巨大导数,只需要让每个小模块知道自己如何反传。
对于目前构建的神经网络,损失函数表达为:
L = 1 N ∑ i = 1 N L i + λ ( R ( W 1 ) + R ( W 2 ) ) L = \frac{1}{N} \sum_{i=1}^{N} L_i + \lambda (R(W_1) + R(W_2))
L = N 1 i = 1 ∑ N L i + λ ( R ( W 1 ) + R ( W 2 ))
其中:
L i = ∑ j ≠ y i max ( 0 , s j − s y i + 1 ) L_i = \sum_{j \neq y_i} \max(0, s_j - s_{y_i} + 1)
L i = j = y i ∑ max ( 0 , s j − s y i + 1 )
R ( W i ) = ∑ m , n ( W i ) m , n 2 R(W_i) = \sum_{m,n} (W_i)_{m,n}^2
R ( W i ) = m , n ∑ ( W i ) m , n 2
如果直接计算损失函数对参数的梯度,计算量会非常大。反向传播通过将计算过程分解为多个步骤,逐层计算梯度,从而大大提高了计算效率。
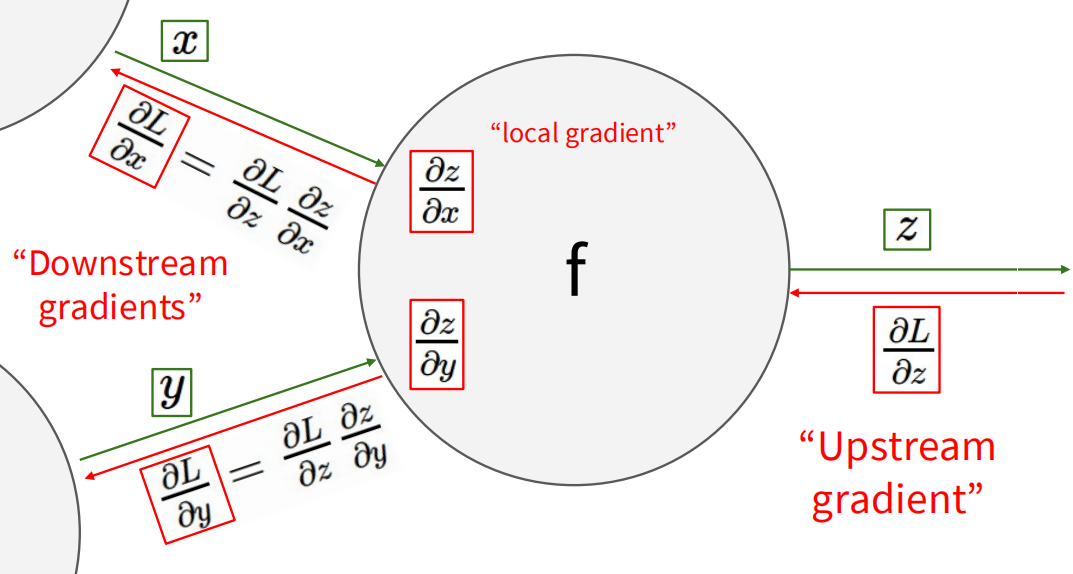
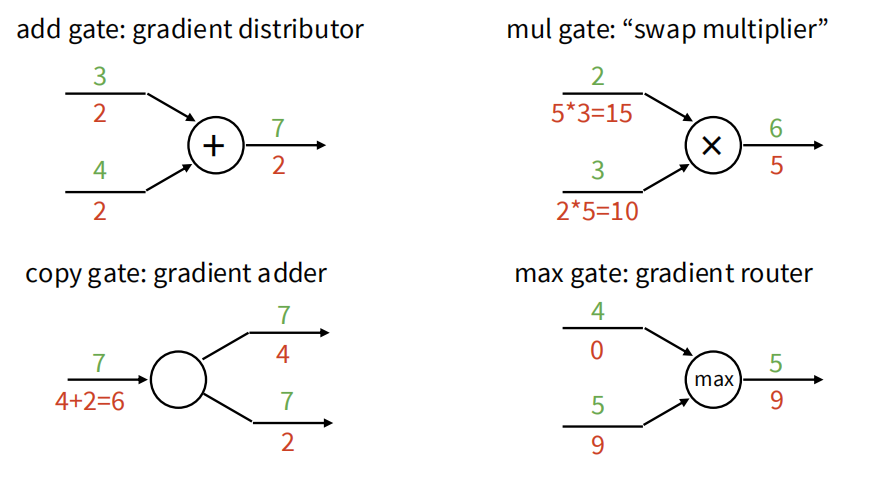
以此图为例,f 从前一层结点接受 x 和 y 两个输入,给出输出 z。反向传播时,f 接收来自后一层的梯度 ∂ L ∂ z \frac{\partial L}{\partial z} ∂ z ∂ L ∂ L ∂ x \frac{\partial L}{\partial x} ∂ x ∂ L ∂ L ∂ y \frac{\partial L}{\partial y} ∂ y ∂ L
读这类图时可以把上游梯度理解为“最终损失对当前输出有多敏感”。当前节点要做的是回答:如果我的某个输入稍微变大一点,我的输出会怎样变?再把这两个敏感度相乘,就得到最终损失对该输入的敏感度。加法门会把梯度原样传给多个输入,乘法门会把另一个输入值作为局部导数,max 或 ReLU 这类门则会根据前向时的取值决定梯度是否通过。
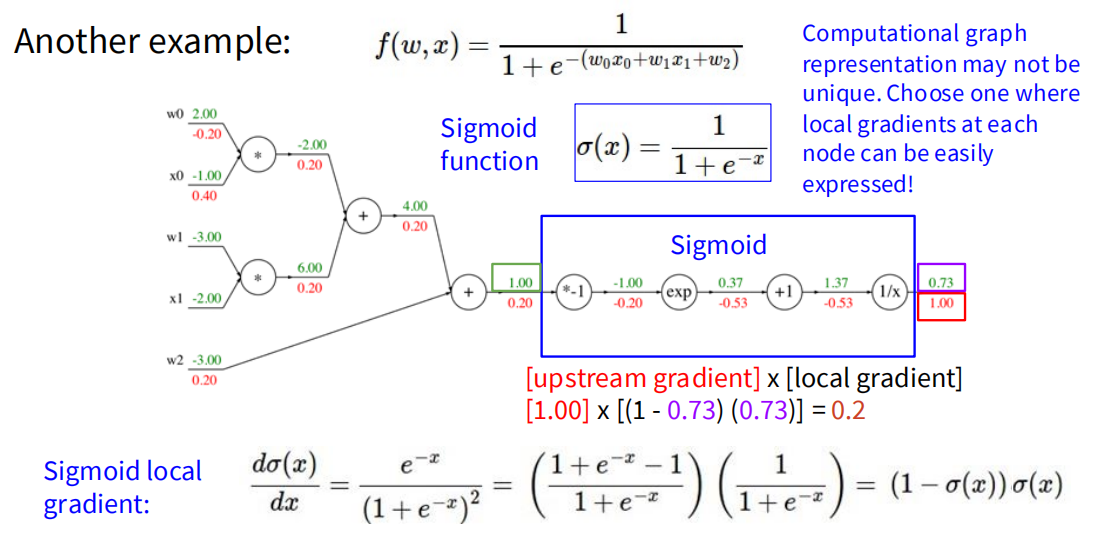
这个图中的例子展示了一个向前和反向传播的过程。值得注意的是虽然其中的 Sigmoid 函数可以分步计算,但实际上可以将 Sigmoid 函数作为一个整体来计算其导数,来简化计算图的表示,计算图可以是不唯一的。整个计算图的代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def sigmoid (x ): """Sigmoid激活函数。""" return 1.0 / (1.0 + np.exp(-x)) def f (w0, x0, w1, x1, w2 ): s0 = w0 * x0 s1 = w1 * x1 s2 = s0 + s1 s3 = s2 + w2 L = sigmoid(s3) grad_L = 1.0 grad_s3 = grad_L * L * (1 - L) grad_w2 = grad_s3 grad_s2 = grad_s3 grad_s0 = grad_s2 grad_s1 = grad_s2 grad_w1 = grad_s1 * x1 grad_x1 = grad_s1 * w1 grad_w0 = grad_s0 * x0 grad_x0 = grad_s0 * w0 return L, (grad_w0, grad_x0, grad_w1, grad_x1, grad_w2)
一些其他示例:
推广到矩阵运算
将之前的简单运算变成矩阵运算:
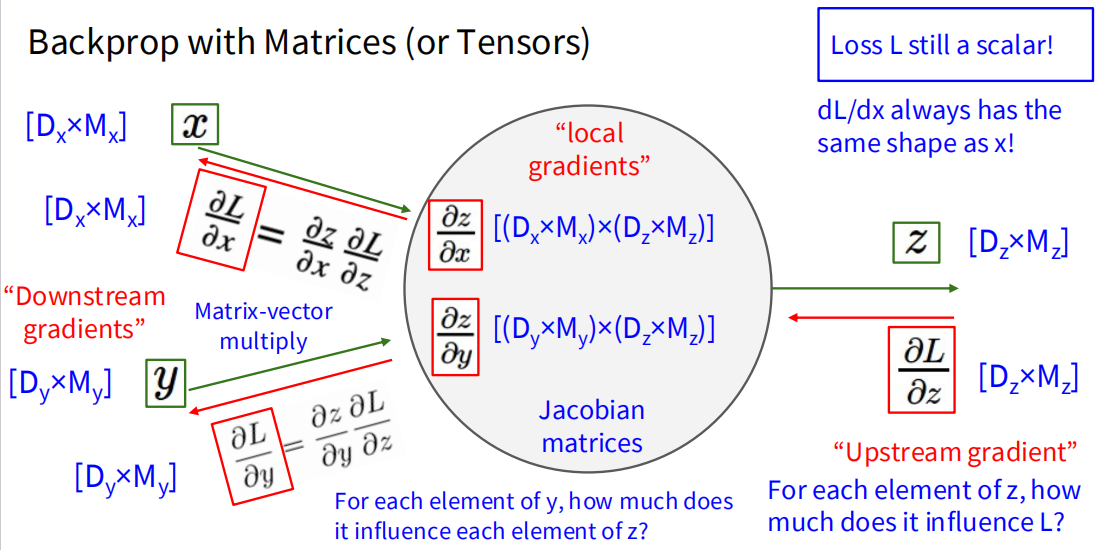
在矩阵乘法中,对于输入的矩阵,损失函数对其梯度的矩阵大小与输入矩阵相同。矩阵中每个位置的值就代表损失函数对其对应输入位置标量的偏导数。下面是矩阵乘法的例子:
为什么不使用 Jacobian 矩阵来表示?因为 Jacobian 矩阵过于庞大,计算和存储都很不方便。反向传播通过逐层计算梯度,避免了显式构建 Jacobian 矩阵,从而提高了计算效率。
矩阵反传最重要的不是死记公式,而是检查形状和依赖关系。若前向是 y = x w y=xw y = x w x x x y y y x x x w T w^T w T w w w w w w x T x^T x T
尝试推一遍:
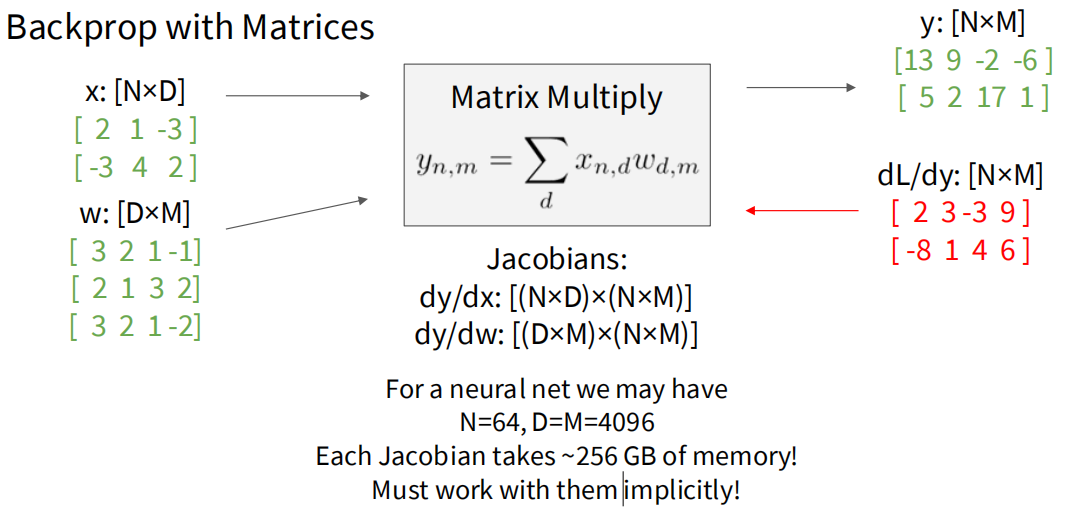
对矩阵乘 y = x w y = xw y = x w y n , m = ∑ d x n , d w d , m y_{n,m} = \sum_{d} x_{n,d} w_{d,m} y n , m = ∑ d x n , d w d , m
其中 x x x ( N , D ) (N, D) ( N , D ) w w w ( D , M ) (D, M) ( D , M ) y y y ( N , M ) (N, M) ( N , M )
现在我们要计算 L L L x n , d x_{n,d} x n , d L L L y y y y y y x n , d x_{n,d} x n , d y y y y y y x n , d x_{n,d} x n , d w w w y n , m y_{n,m} y n , m x n , d x_{n,d} x n , d w d , m w_{d,m} w d , m
那么如何选取这些 y y y x x x y y y x n , m x_{n,m} x n , m y y y n n n L L L y y y n n n y y y x n , d x_{n,d} x n , d
∂ L ∂ x n , d = ∑ m ∂ L ∂ y n , m ⋅ ∂ y n , m ∂ x n , d = ∑ m ∂ L ∂ y n , m ⋅ w d , m \frac{\partial L}{\partial x_{n,d}} = \sum_{m} \frac{\partial L}{\partial y_{n,m}} \cdot \frac{\partial y_{n,m}}{\partial x_{n,d}} = \sum_{m} \frac{\partial L}{\partial y_{n,m}} \cdot w_{d,m}
∂ x n , d ∂ L = m ∑ ∂ y n , m ∂ L ⋅ ∂ x n , d ∂ y n , m = m ∑ ∂ y n , m ∂ L ⋅ w d , m
然后再推广到梯度矩阵。在上面得到的式子中,将 ∂ L ∂ y \frac{\partial L}{\partial y} ∂ y ∂ L n n n w w w d d d ∂ L ∂ x \frac{\partial L}{\partial x} ∂ x ∂ L ( n , d ) (n,d) ( n , d ) ( N , M ) (N, M) ( N , M ) ( D , M ) (D, M) ( D , M ) ( N , D ) (N, D) ( N , D ) w w w ∂ L ∂ y \frac{\partial L}{\partial y} ∂ y ∂ L ( N , D ) (N,D) ( N , D )
∂ L ∂ x = ∂ L ∂ y ⋅ w T \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot w^T
∂ x ∂ L = ∂ y ∂ L ⋅ w T
同理可得:
∂ L ∂ w = x T ⋅ ∂ L ∂ y \frac{\partial L}{\partial w} = x^T \cdot \frac{\partial L}{\partial y}
∂ w ∂ L = x T ⋅ ∂ y ∂ L
长得很对称,记起来还是很方便的,不禁感慨于数学的美感,也发现自己的线代基础真是稀烂。