
ADS-05:KD 树
多维二叉搜索树,通常简称为 KD Tree 或 k-d tree,其中 k 代表搜索空间的维度)是一种用于在高维空间中组织和存储数据点的空间划分数据结构 。该理论由 Jon Louis Bentley 于1975年首次提出,其开创性的学术论文《Multidimensional Binary Search Trees Used for Associative Searching》荣获了1975年 ACM 学生论文竞赛二等奖。
在该论文中,Jon Bentley 确立了 KD 树作为一种解决关联检索问题的核心数据结构。在早期的数据库应用中,信息检索往往依赖于单一主键,而面对包含多个属性键值的复杂查询时,传统的线性扫描或单维索引结构性能急剧衰退 。KD 树的提出证明了单一的树状数据结构能够极为高效地处理多种复杂的高维查询请求 。
为了量化评估该数据结构的理论优越性,以下表格展示了 KD 树在处理包含 个记录的数据集时,各类底层效用算法的渐进时间复杂度表现:
| 算法操作类别 | 理论时间复杂度表现 | 核心计算逻辑与特性说明 |
|---|---|---|
| 节点插入(Insertion) | 在保持树平衡的前提下,沿树高向下遍历至叶子节点完成插入,平均访问节点数与树高成正比 。 | |
| 根节点删除(Deletion of the root) | 删除根节点需要寻找合适的后继节点进行替换,这涉及在多维子树中跨维度寻找最值,代价较普通搜索更高 。 | |
| 随机节点删除(Deletion of a random node) | 对于一般叶子节点或低度数内部节点的删除,结构调整代价较低,维持对数级复杂度 。 | |
| 树结构优化(Optimization) | 重新构建并优化整棵树的拓扑结构,确保后续的所有检索操作都能获得严格的对数级性能保证 。 | |
| 指定键值的偏匹配查询(Partial match queries) | 当在 维空间中指定 个关键字(Keys)进行查询时,被证明的最大运行时间边界 。 | |
| 最近邻查询(Nearest neighbor queries) | 在数据分布较为均匀的情况下,经验观察(Empirically observed)所得的平均检索运行时间 。 |
这些性能指标在提出之时远超当时已知的最佳算法,并确立了 KD 树在处理交叉查询(Intersection queries)、最近邻查询以及偏匹配查询中的理论统治地位 。
A Complete (Balanced) BST
定义
在深入探讨多维空间划分之前,必须首先确立一维空间下完全平衡二叉搜索树(Complete Balanced Binary Search Tree, BST)的基本代数性质与拓扑结构。KD 树在本质上是标准二叉搜索树向多维几何空间的自然推广 。对于树中的任意内部节点 ,其键值(Key)的分布规律必须满足严格的数学等式约束:
这一公式在代数与数据结构层面具有深刻的含义。它表明,对于任意节点 ,其自身的键值在数值上严格等于其右子树()中所有节点键值的最小值。同时,这一最小值恰好等于该节点在中序遍历意义下的直接后继节点的键值 。基于这一核心等式,可以推导出二叉搜索树的经典左、右子树空间隔离特性:
其一为左子树严格有界特性,即 。这意味着左子树()中的每一个节点 ,其键值都必须严格小于当前父节点 的键值 。 其二为右子树半闭包特性,即 。这意味着右子树中的任意节点 ,其键值必须大于或等于当前父节点的键值 。
在此数据结构拓扑上,基础的搜索算子 search(x) 被赋予了明确的语义边界:该函数不仅用于寻找精确匹配的值,更核心的作用是返回树中“不大于目标值 的最大键值”。这种对几何边界点的精确收敛查找,是后续在多维空间中进行区间范围裁剪与空间相交测试的底层机制。
最近公共祖先
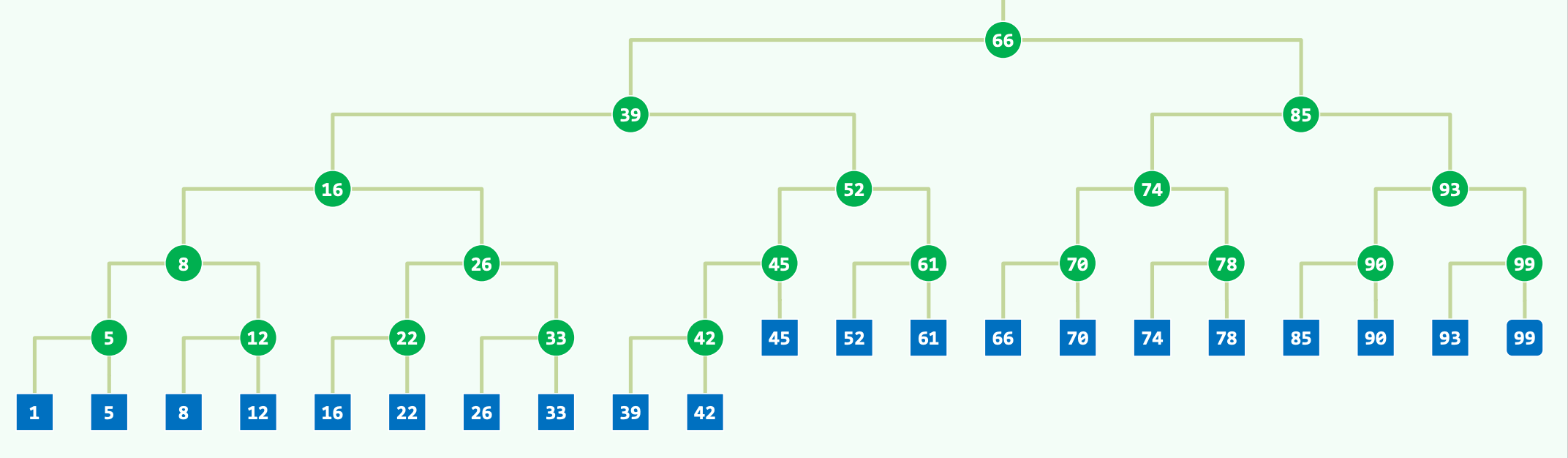
在一维平衡二叉搜索树中执行区间范围查询时,首要的计算任务是确定目标查询区间在树拓扑结构中的分歧点,这一分歧点在图论中被称为最近公共祖先(Lowest Common Ancestor, LCA)。LCA 的确定有效地将单一的区间扫描转化为两套独立的边界树遍历路径,从而极大地缩小了搜索空间。
以一个具体的数值区间查询为例,假设我们需要在平衡二叉树中检索落在区间 内的所有数据点 。算法的执行路径并非盲目遍历,而是首先调用边界试探函数。系统会并行或串行地执行两次边界收敛查询: 首先执行 search(17),根据二叉搜索树的特性,算法会沿着节点向下收敛,最终返回节点 16。此时,节点 16 在数值上小于查询下界 17,因此它可能处于有效区间之外,在后续处理中存在被拒绝的概率 。 随后执行 search(79),算法向右侧拓扑收敛,最终返回节点 78。由于 78 严格落在闭区间内部,该节点在后续结果集中必然被接受。
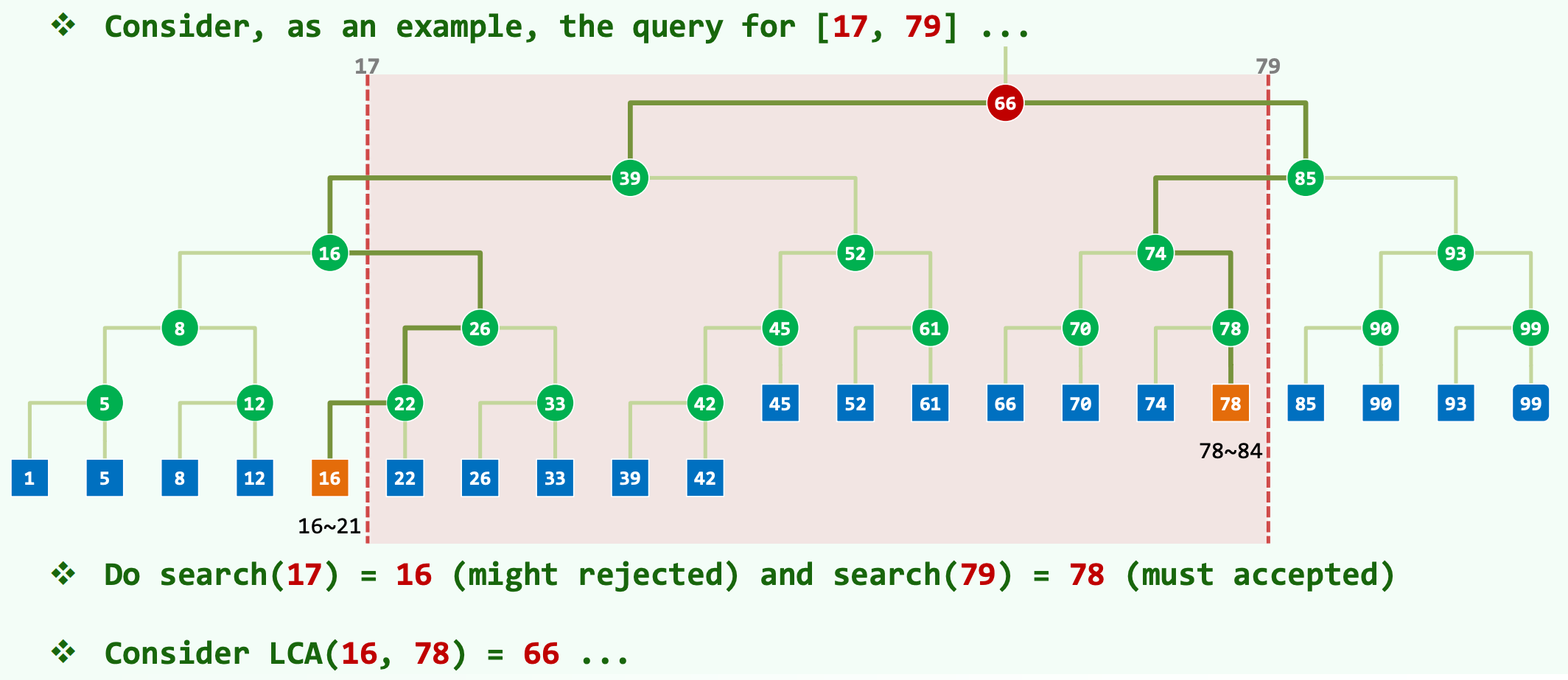
在明确了下界节点 16 与上界节点 78 之后,算法的核心转移至求解这两个节点在树中的最近公共祖先,即计算 LCA(16, 78)。通过树的自底向上回溯或双指针下降匹配,可以得出其最近公共祖先为节点 66 。在节点 66 这一拓扑枢纽处,目标区间的几何形态决定了搜索路径的必然分岔:目标区间的下界(17)迫使搜索路径必须向左子树深入探查,而目标区间的上界(79)则指示搜索路径必须向右子树展开 。LCA 节点构成了该范围查询的拓扑最高点,所有高于 LCA 的树节点均无需纳入范围相交测试的考量范围内。
Union of Disjoint Subtrees
在精确定位最近公共祖先之后,算法进入范围查询的核心优化阶段:不相交子树的对数级提取与合并。传统线性扫描需要逐一验证区间内的每一个点,而在平衡二叉搜索树中,算法通过提取完整的子树来实现批量的结果报告。从 LCA(节点 66)开始,算法需要沿着前往下界(节点 16)的路径 path(16) 以及前往上界(节点 78)的路径 path(78) 再次进行深度遍历 。
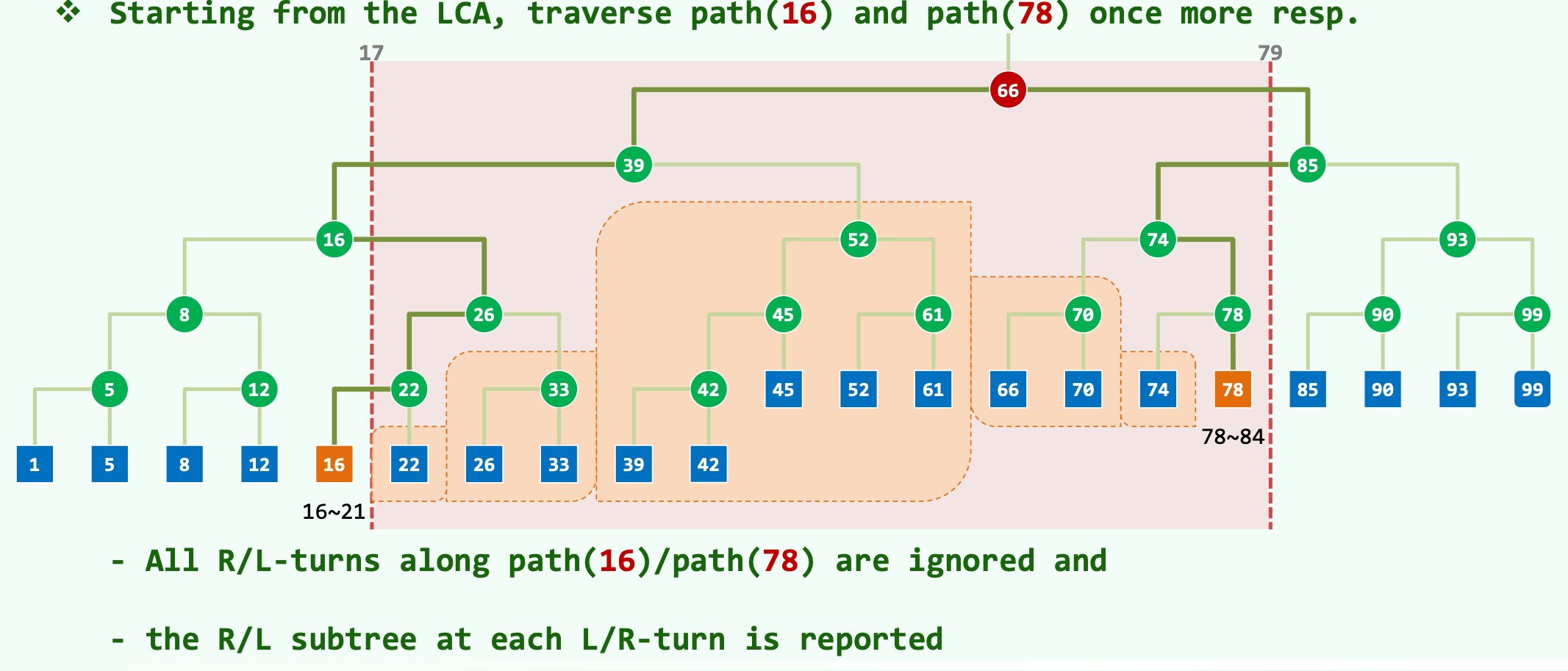
在这一阶段,算法采用了一种基于树形拓扑的转向剪枝验证逻辑。具体机制详述如下:
针对左侧下界边界路径 path(16) 的遍历:当搜索路径从一个父节点向下移动时,如果发生向右侧的偏转,这意味着左子树中的所有节点均小于查询下界,因此这些节点连同整个左子树被整体忽略。反之,如果搜索路径发生向左侧的偏转,这一几何转向具有极其重要的代数意义:当前节点的值必定大于下界 17,同时由于它位于 LCA(66)的左子树中,其值也必定小于上界 79。由此可以推导出,该节点右子树中的所有元素不仅严格大于当前节点(从而大于下界),而且必定小于上界。因此,该右侧子树被视为一个完全合法的规范集合,作为一个整体直接被报告,算法无需再进入该子树进行任何逐点验证 。
针对右侧上界边界路径 path(78) 的遍历,剪枝逻辑呈现完美的对称性。如果搜索路径发生向左侧的偏转,说明当前父节点的右子树全部超出了区间上界 79,故整个右子树被直接忽略。如果路径发生向右侧的偏转,则表明当前节点的左子树必然严格介于 LCA 节点与当前节点之间,从而完美地落在查询区间 的内部。此时,该左侧子树被作为一个整体直接输出报告 。
这种忽略所有向外侧偏转路径,并在每一次向内侧偏转时整体报告对立侧子树的机制,极大地减少了冗余的节点访问 。最终的查询结果集,不再是由离散的单个数据点构成,而是被表示为 个互不相交的规范子树的并集。
复杂度分析
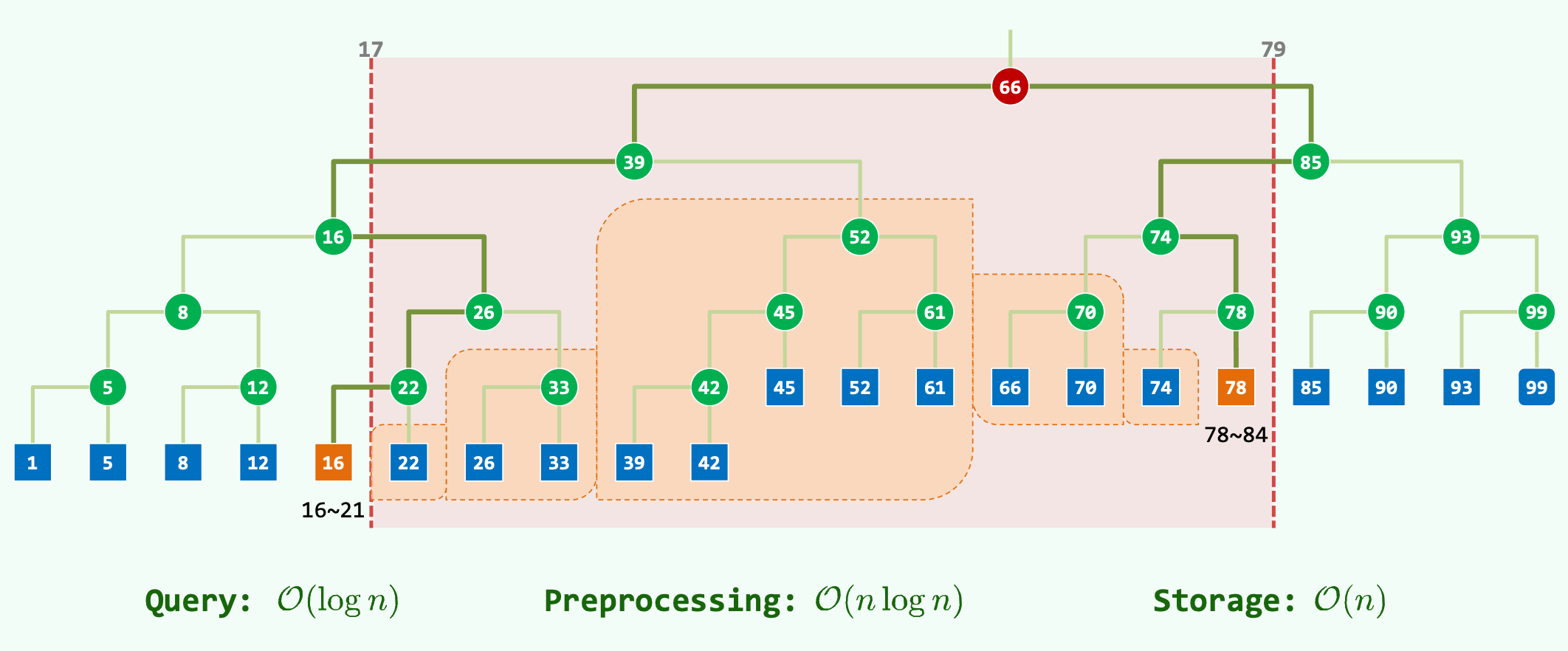
一维平衡二叉搜索树在处理区间范围查询时,其卓越的理论基础直接反映在各类操作的渐进复杂度指标上。以下表格对算法的查询耗时、预处理成本以及内存消耗进行了严谨的评估 :
| 复杂度评估维度 | 渐进时间/空间复杂度 | 理论推导与工程实现意义 |
|---|---|---|
| 范围查询(Query) | 算法查找 LCA 并沿两侧路径下探深度的过程受限于树高 。若需将符合条件的子树节点全量枚举,则需附加 的输出代价,其中 为实际落入区间的结果总数 。 | |
| 数据预处理(Preprocessing) | 采用分治策略构建最优树结构需要对原始数据进行全局排序或重复执行中位数查找。诸如快速排序或归并排序的理论下界决定了预处理过程为 。 | |
| 结构存储(Storage) | 二叉搜索树通过指针直接链接各数据节点,无需构建高维空间下的冗余网格或附加辅助索引。总节点数严格等于数据规模 ,在内存管理上展现出极致的紧凑性 。 |
这些复杂度指标奠定了计算几何的基础,并且为后续将数据结构由一维扩展至多维几何空间提供了性能比较的基准。
KD 树
Divide-And-Conquer
一维平衡二叉搜索树虽然在处理单轴数据时表现出色,但其拓扑结构无法直接应对涉及多个坐标维度的平面几何范围搜索(Planar Geometric Range Search, GRS)。为了将对数级检索的方法论推广至多维空间,KD 树引入了计算科学中经典的分治法策略,通过递归的方式将高维空间的复杂划分问题降维转换为一系列独立的一维切分问题 。
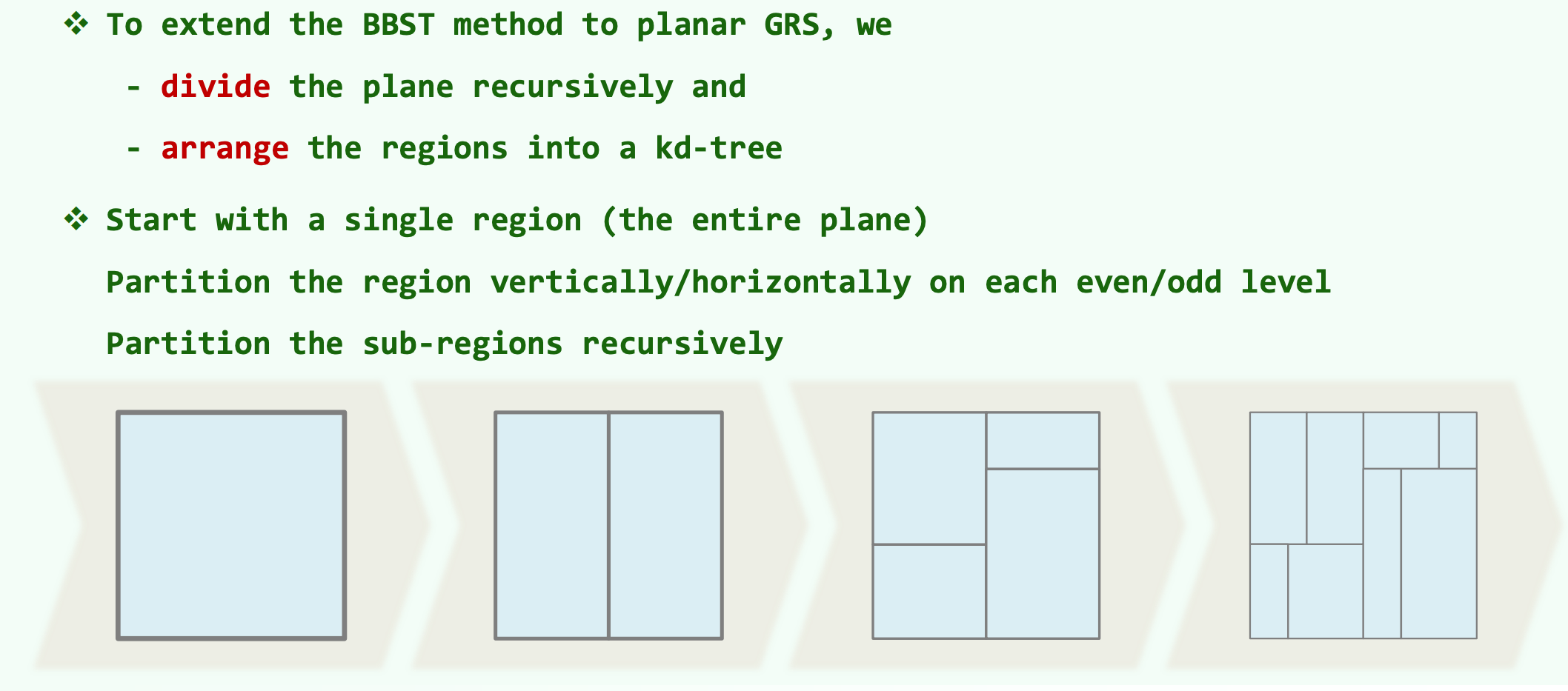
KD 树的空间构建逻辑从一个包含整个数据集的单一且无限大的初始区域(即整个平面或多维超空间)开始 。其核心的递归分治步骤如下:
在树结构的拓扑层级推进中,算法采用交替维度的切分方式。具体而言,在树的每一个偶数层(假定根节点位于第0层),算法仅关注数据点的第一维度(例如二维平面中的 X 轴),并生成一条垂直于 X 轴的分割线,将当前空间切分为左右两个子半平面。随后,当递归深入至树的奇数层时,算法切换至第二维度(例如 Y 轴),生成一条垂直于 Y 轴的水平分割线,将当前的子空间进一步切分为上下两部分 。
通过这种在各个维度间循环交替切分的机制,算法对每一个生成的子区域进行无休止的递归划分,直至子区域内仅包含单一的数据点或成为空集 。这一机制巧妙地将多维空间转化为严格嵌套的矩形包围盒结构,保留了二叉树的高效性。
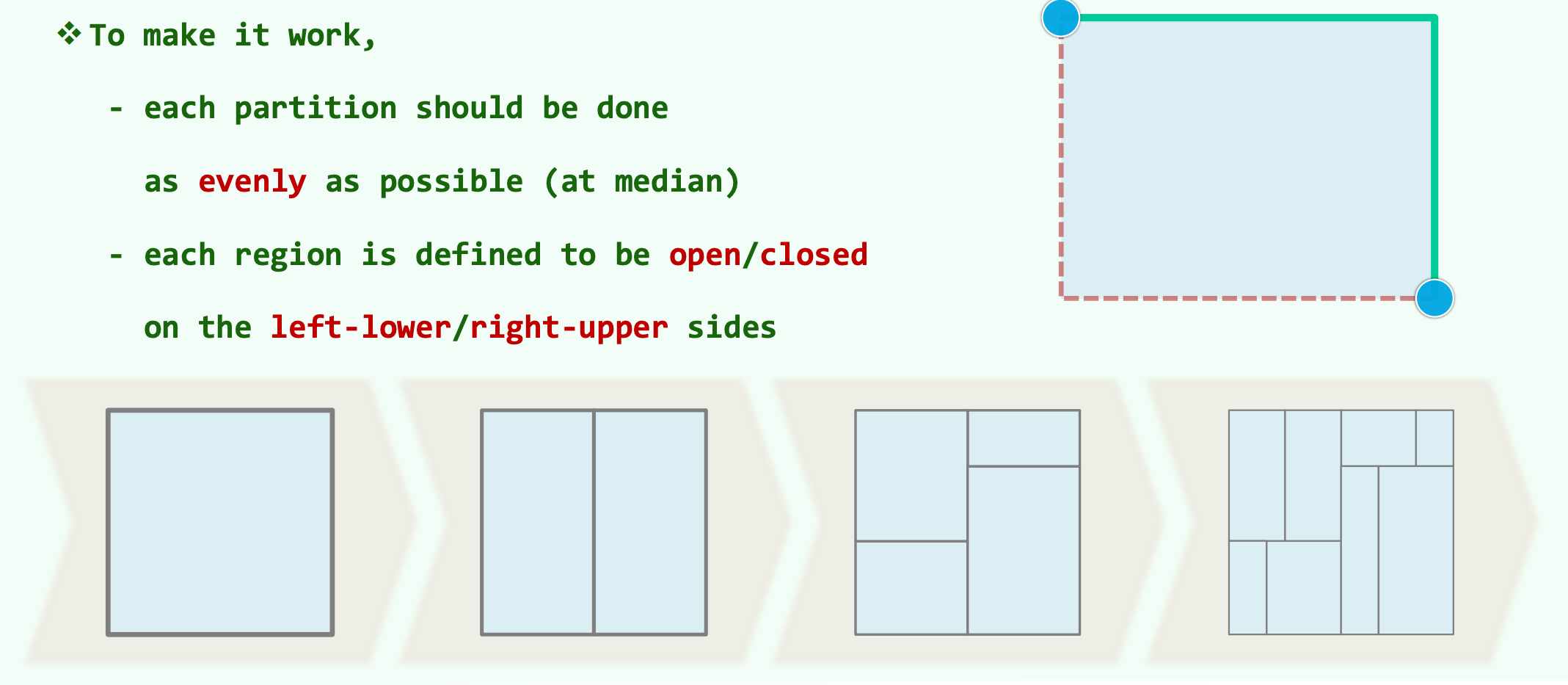
为了确保分治策略在极端数据分布下依然能够保持理论上的最佳时间复杂度,空间切分算法在工程实现与代数约束上必须遵循两项极其严苛的设计细节 。
-
首先是切分的均匀性约束。为了使最终构建的 KD 树成为一棵严格平衡的二叉树,算法被强制要求每一次的空间切分都必须尽可能均匀地将当前区域内的数据点一分为二。在数学实现上,这意味着在当前激活的切分轴上,算法不能随机选择切分点,而是 必须精确计算出当前子集坐标序列的几何中位数作为绝对的分割边界 。这一强制要求避免了树结构的退化,确保了树的最大深度严格收敛于 。
-
其次是区域边界的拓扑开闭性定义。在连续几何空间中,落在分割线上的数据点极易引发归属歧义。为了在代数上消除这种模棱两可的状态,KD 树将所有子区域的边界进行了非对称的闭合度定义。具体规定为, 每一个矩形区域在左下侧边界被定义为开区间,而在右上侧边界被定义为闭区间 。通过这种严密的集合半开半闭属性定义,系统可以确保无论数据点在空间中如何聚集或重叠,平面上的任意一个坐标点都且仅从属于唯一的一个叶子节点,保障了数据索引的一致性。
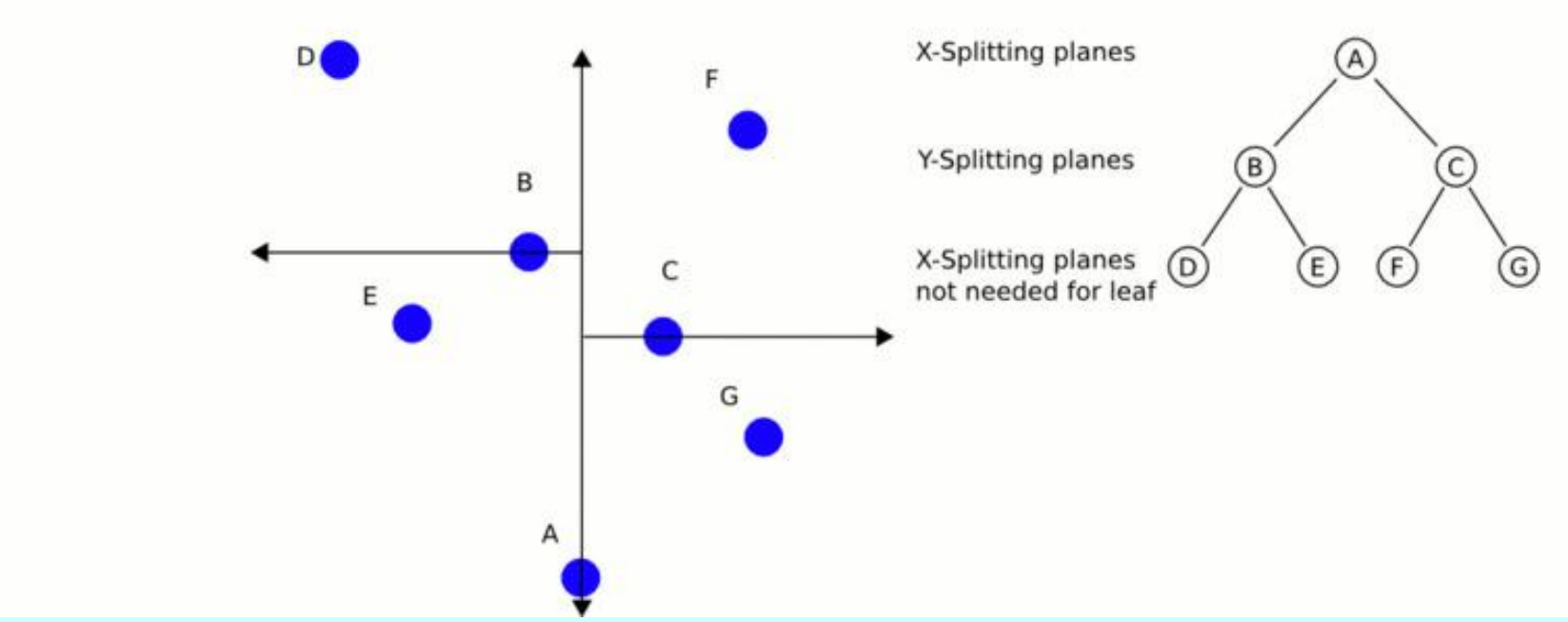
通过一个具体的二维平面散点图示例,可以直观地解析上述中位数选取与交替切分的执行轨迹。假设存在一个包含 A、B、C、D、E、F、G 共7个数据点的二维平面,KD 树的递归切分过程呈现出层层嵌套的几何美感 :
在初始阶段,算法接管整个平面,并激活 X 轴。通过线性选择算法,在 X 轴的坐标投影中找到中位数所在的垂直分割线 。此时,平面被一分为二,点 C 恰好作为中位枢纽位于该分割线上,部分数据点被划入左侧半平面,其余数据点则归入右侧。
进入第二阶段,针对 左侧的子空间,算法切换至 Y 轴。在左侧的剩余数据点中,寻找 Y 坐标的中位数,并以此绘制一条水平分割线 。同时,在 右侧的子空间中,独立计算右侧数据点 Y 坐标的中位数,绘制出相应的水平分割线 。至此,整个平面被切分为四个非等面积的独立矩形区域。
进入第三阶段,算法再次回到 X 轴。针对由 和 生成的四个子区域,分别计算区域内部的 X 轴中位数,并绘制出新的垂直分割线 、 以及 。随着层级的加深,交替使用垂直线和水平线进行切割,最终每一个数据点均被独立隔离在一个微小的矩形细胞中,整个空间形成了一种类似于蒙德里安抽象画的拓扑划分。
性能对比:四叉树
在处理二维或三维空间划分时,四叉树是常被用来与 KD 树进行对比的另一种经典数据结构。尽管两者均致力于解决空间降维问题,但其内在的切分哲学与拓扑代价存在显著差异 。以下表格详细对齐了两种数据结构的核心技术特征:
| 对比维度 | KD 树 | 四叉树 |
|---|---|---|
| 空间切分策略 | 数据驱动。依赖数据点的中位数作为切分基准,自适应于数据的密集程度 。 | 空间驱动。通常选取几何空间的中心点进行强制对等切分,忽略数据分布规律。 |
| 维度切分时序 | 轴交替。在同一拓扑深度,只对一个维度(水平或垂直)进行一次切分 。 | 同步切分。在每个节点同时使用水平和垂直两条线,将空间直接划分为四个象限(NW, NE, SW, SE)。 |
| 节点分支因子 | 恒为 2。即使推广到极高维空间,每个节点依然只有两个子分支,指针开销低 。 | 指数级扩展。在二维空间为4个分支,在 维空间中(如八叉树等)分支数将呈 暴增。 |
| 拓扑树高与平衡性 | 绝对平衡。利用中位数切分确保树高严格保持在 。 | 极易失衡。在数据高度偏斜的区域,可能产生大量的空分支节点和极深的嵌套层级。 |
由此可见,KD 树在保持数据结构简洁性的同时,提供了更为稳健的最坏情况性能保证,特别是在处理维度较高且分布不均的密集点云数据时,四叉树极易遭遇存储空间与树高的双重恶化。
buildKdTree
将上述二维平面的分治几何逻辑转化为可执行的计算机代码,其核心在于一个名为 buildKdTree 的递归函数。该函数接收数据点集 以及当前的递归深度 作为输入参数。源文件中所展示的构建算法伪代码被完整保留,并对其执行机制与时间复杂度进行详尽推导:
1 | buildKdTree(P, d) |
对该算法各执行步骤的深度解析如下: 算法首先确立了递归退出的基线条件(Base case)。当传入的子集 仅包含单一的孤立点 {p} 时,递归终止,算法调用 CreateLeaf(p) 实例化一个叶子节点并立即返回 。 若集合 包含多个点,算法则分配内存实例化一个全新的内部节点 CreateKdNode()。接下来,算法利用模运算机制 Even(d)? VERTICAL : HORIZONTAL,基于当前树深度 的奇偶性,动态赋予该节点具体的切分轴(X轴或Y轴)。
算法的计算性能瓶颈在于 FindMedian 操作。为了确保二叉树的完美平衡,算法必须在当前的切分轴上寻找到点集序列的中位数,并以此坐标点为基准建立超平面(splitLine)。在未预排序的数组中寻找中位数,若采用诸如 Median-of-Medians 或 Quickselect 等线性时间选择算法,其最坏或平均时间复杂度为 (此处代码注释特意标注了 O(n)! 以警示其计算密集型特征)。 在确立分割线后,算法调用 Divide 函数,执行标准的分治逻辑(Divide-And-Conquer, DAC)。所有在切分维度上小于中位数的点被划分入子集 ,大于或等于中位数的点被划分入子集 。最后,算法在 和 上启动递归(Recurse),深度加深为 ,并将返回的子树根节点分别挂载至当前节点的左、右孩子指针(lChild 与 rChild)。
通过引入主定理可以严密推导出该递归算法的时间复杂度。设构建包含 个数据点的 KD 树总耗时为 。在递归的每一层,寻找中位数以及划分两个子集的操作耗时为线性的 。随后,问题被均匀划分为两个规模为 的子问题进行递归。因此,我们得到标准的递归关系式 :
这一公式是快速排序和归并排序中极其经典的递归形式,其推导的最终解析解为 。这从理论上证实了,构建一棵静态的、全平衡的 KD 树具有极高的预处理效率。
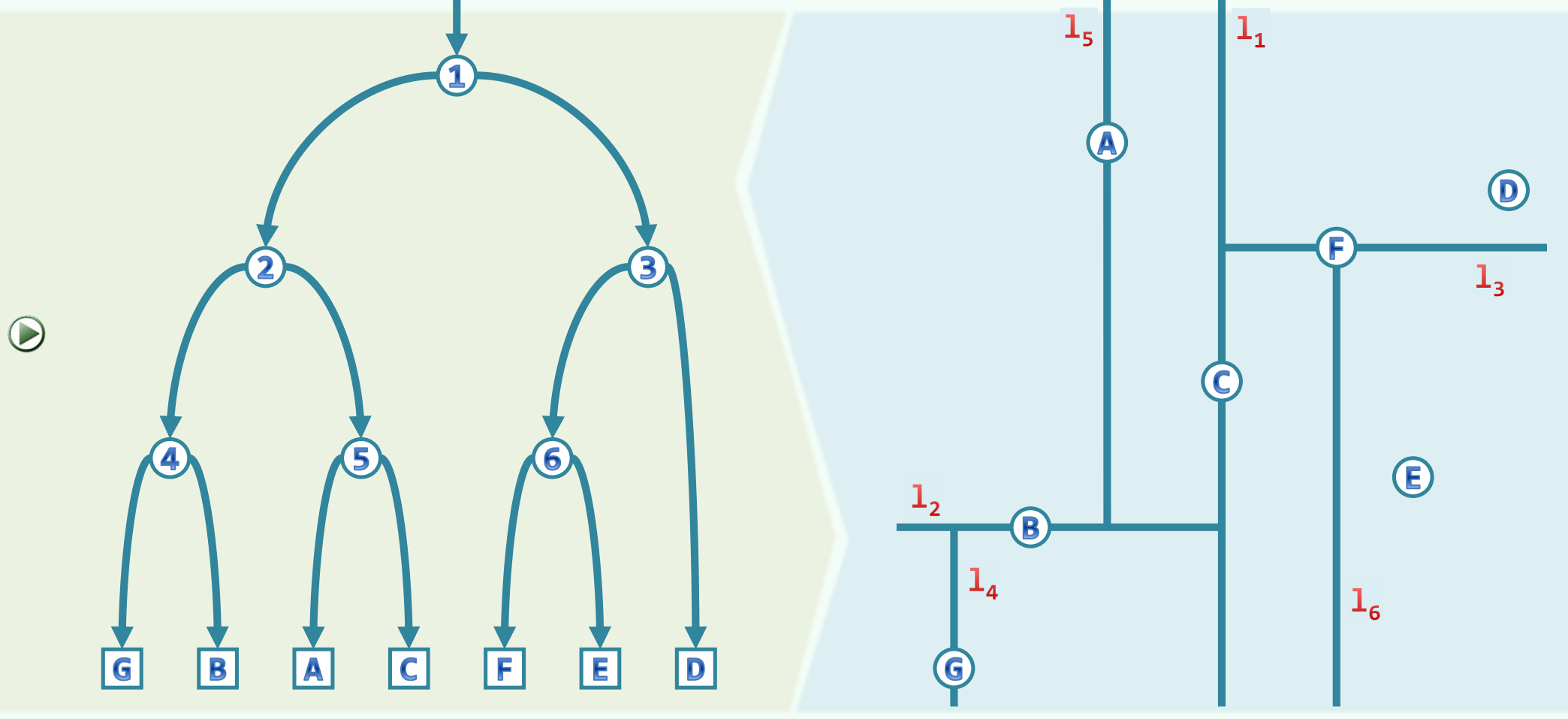
为了将算法代码与前文的二维空间切割示例进行映射,我们可以观察集合 {A,B,C,D,E,F,G} 的具体代数切分过程 :
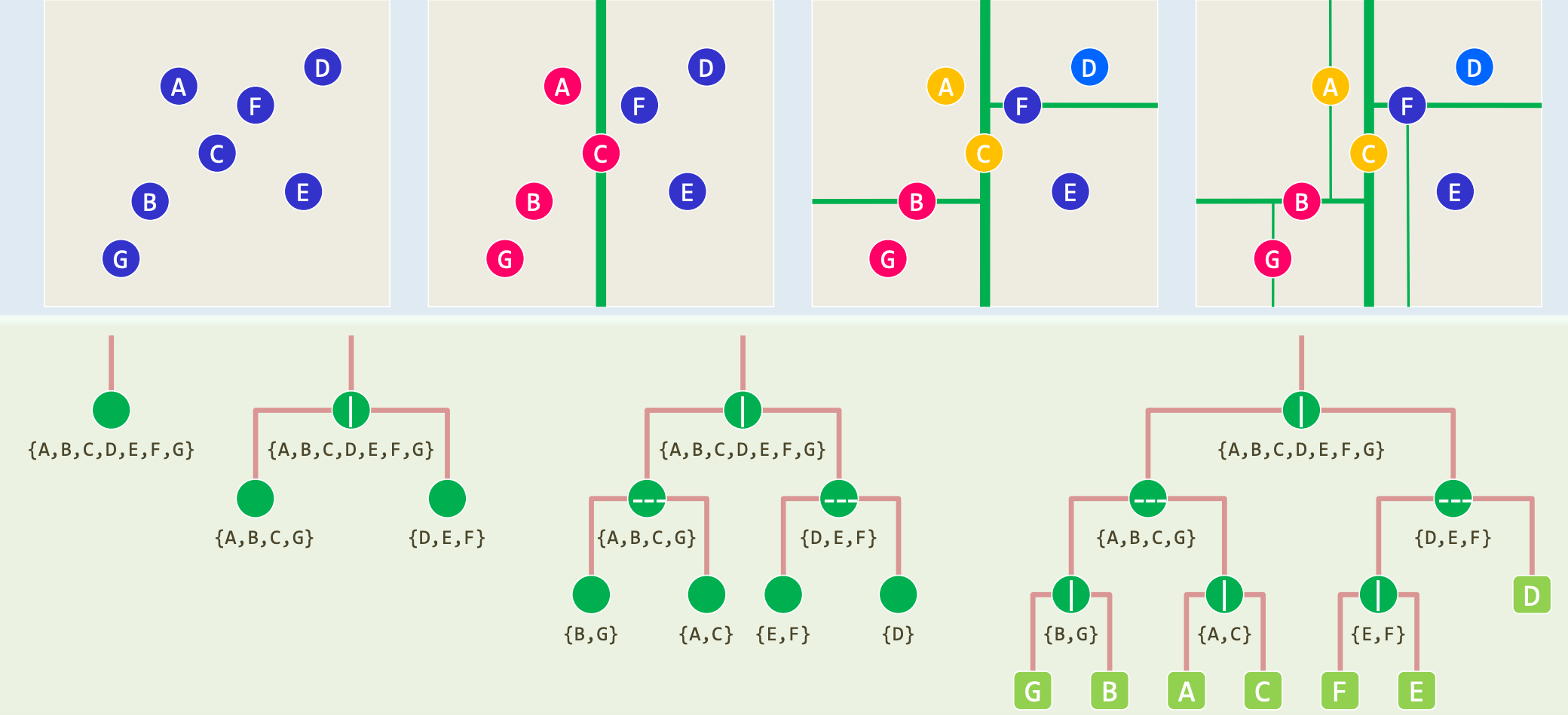
在根节点层(深度为0,垂直切分),依据 X 轴坐标寻找中位数,点 D 被选为切分枢纽。因此,初始的全集 {A,B,C,D,E,F,G} 被拆解。其中,坐标较小的 {A,B,C,G} 被分入左侧子树,而坐标较大的 {E,F} 连同中位点本身构成了右侧分支的考量范围。
在深度为1的层级(水平切分),针对左侧子集 {A,B,C,G},算法切换至 Y 轴,寻找到点 B 作为新的中位枢纽,从而进一步将该子集撕裂为位于上方的 {A,C} 以及位于下方的 {G}。对称地,右侧分支也基于 Y 轴坐标被分割。
通过这种集合的层层剥离与降维,复杂的空间拓扑关系被完美编码为了一棵深度的二叉树图谱。
应用——范围查询
规范子集
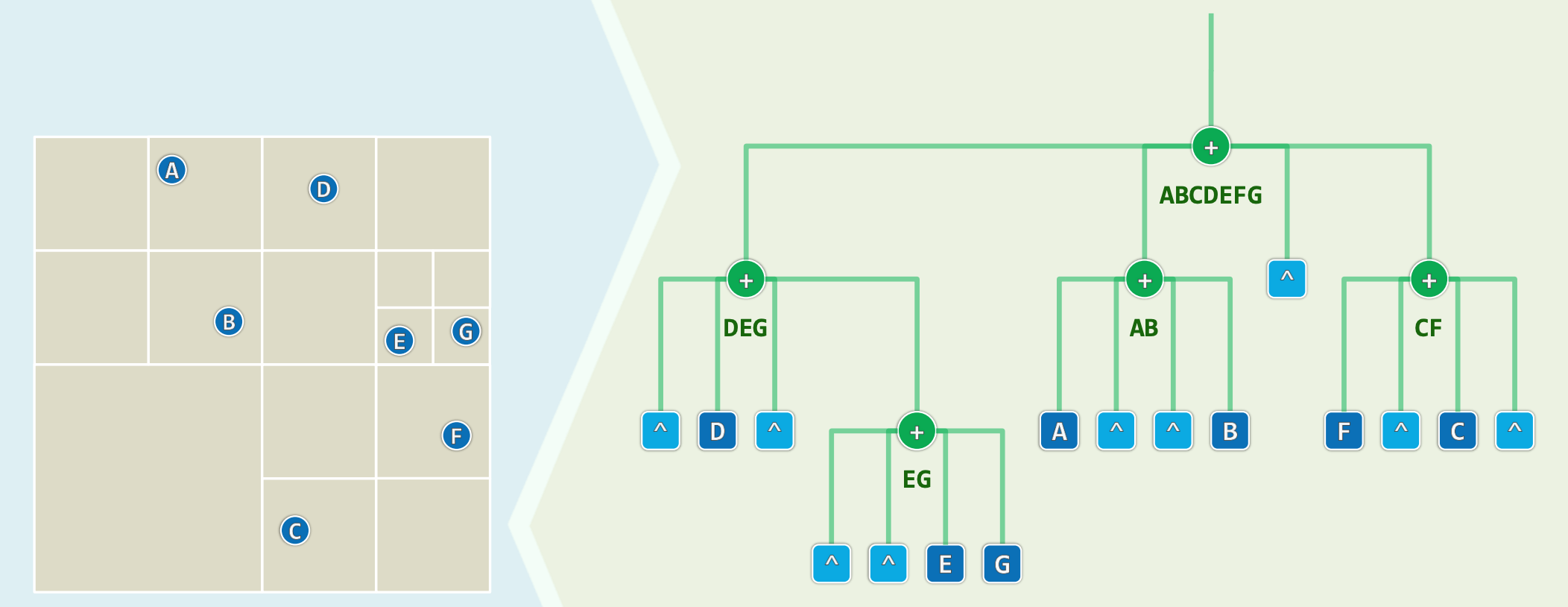
在 KD 树的计算几何语境中,每一次基于中位数的切分都赋予了二叉树内部节点特定的拓扑与集合双重语义。每一个节点不仅仅是内存中的一块数据结构,它在几何上严格对应着平面上的一个矩形子区域,在集合论上则精确映射着被完全包围在该矩形区域内部的数据点子集。在专业领域,这种通过预先计算并绑定在节点上的点集结构,被统称为规范子集(Canonical Subset)。
规范子集的存在为范围查询的效率跃升提供了理论基石,其具备三大核心的代数与拓扑属性: 首先,满足并集守恒定律。对于任何一个树中的内部节点 ,以及它的左孩子 和右孩子 ,必然成立等式:。即父节点的几何区域完美等价于其左右子节点区域的空间拼接 。 其次,满足同层不相交特性。所有位于树结构同一深度的节点,其所代表的几何子区域彼此之间绝对互斥,永远不会产生空间重叠。 最后,满足全空间覆盖特性。若将同一深度的所有内部节点的子区域进行合并,其并集将天衣无缝地覆盖整个初始平面空间。
凭借规范子集的这些优美性质,任何一个复杂的二维几何范围搜索请求,在执行时都无需对数以万计的数据点进行逐个位置的代数判断,而是可以被优雅地解析为提取并合并若干个完全符合条件的规范子集。这一理论上的突破,是计算几何解决海量空间索引问题的本质所在。
从视觉直观的角度理解规范子集,可以想象前文所述的由分割线 至 交织而成的蒙德里安式网格 。当一个矩形的查询窗口被投射到这个网格平面时,它会完全覆盖某些内部节点所代表的矩形区域,同时切割并部分穿过另外一些区域。那些被完全覆盖的矩形网格,就是被查询命中的“规范子集”。算法能够直接将这些网格内绑定的全部点集作为一个完整的批次提取出来,从而彻底规避了深入底层的穷举运算。
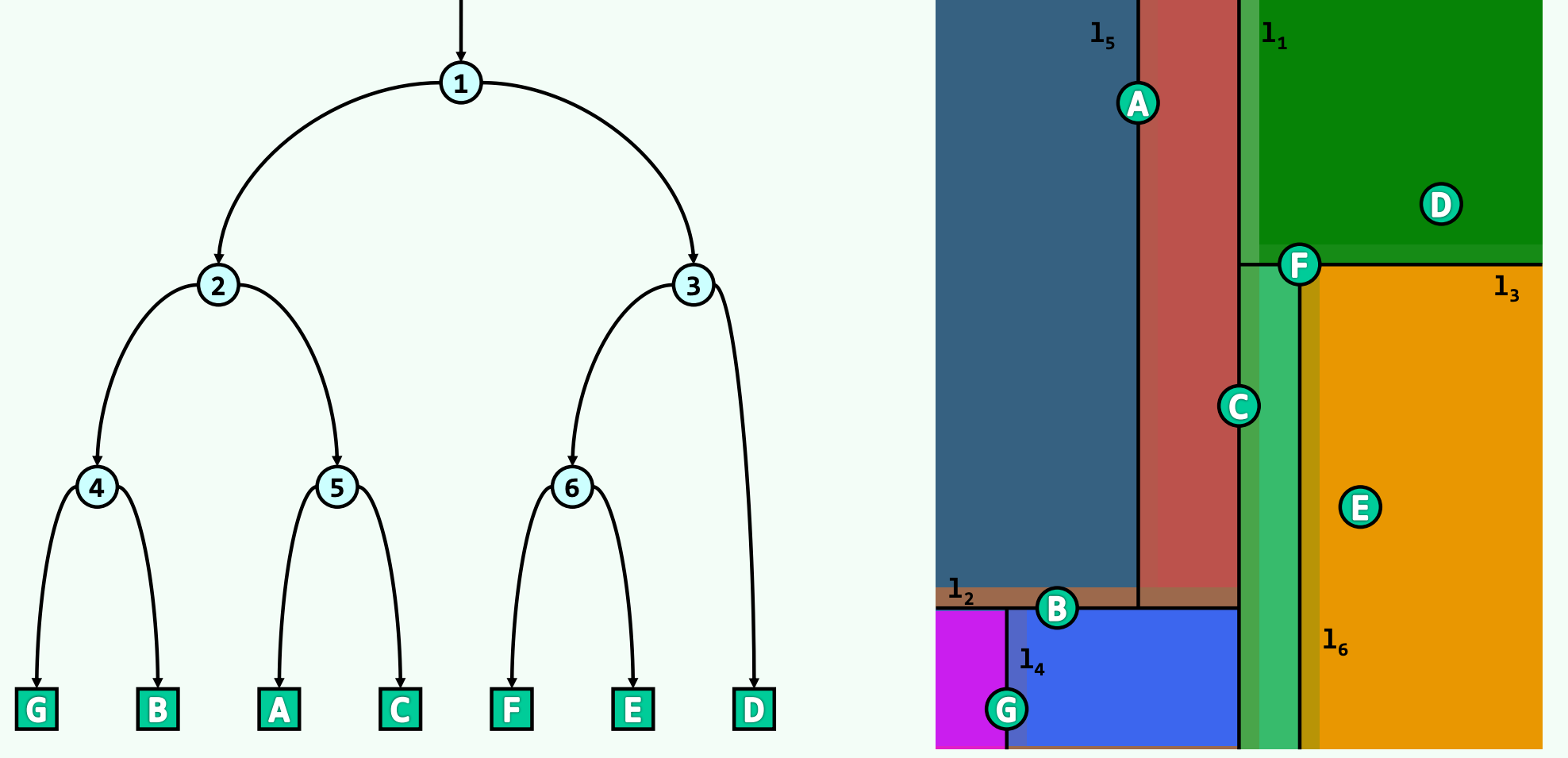
kdSearch
基于规范子集的数学原理,在 KD 树中执行空间范围查找的算法被封装在 kdSearch(v, R) 中。该算法接收当前树节点指针 v 以及一个定义了查询范围的几何对象 R 作为输入。由于其在执行时能够极其干脆地对空间进行大面积的裁剪过滤,该过程被形象地比喻为“热刀来切千(logn)层巧克力”。C++ 伪代码和图示如下:
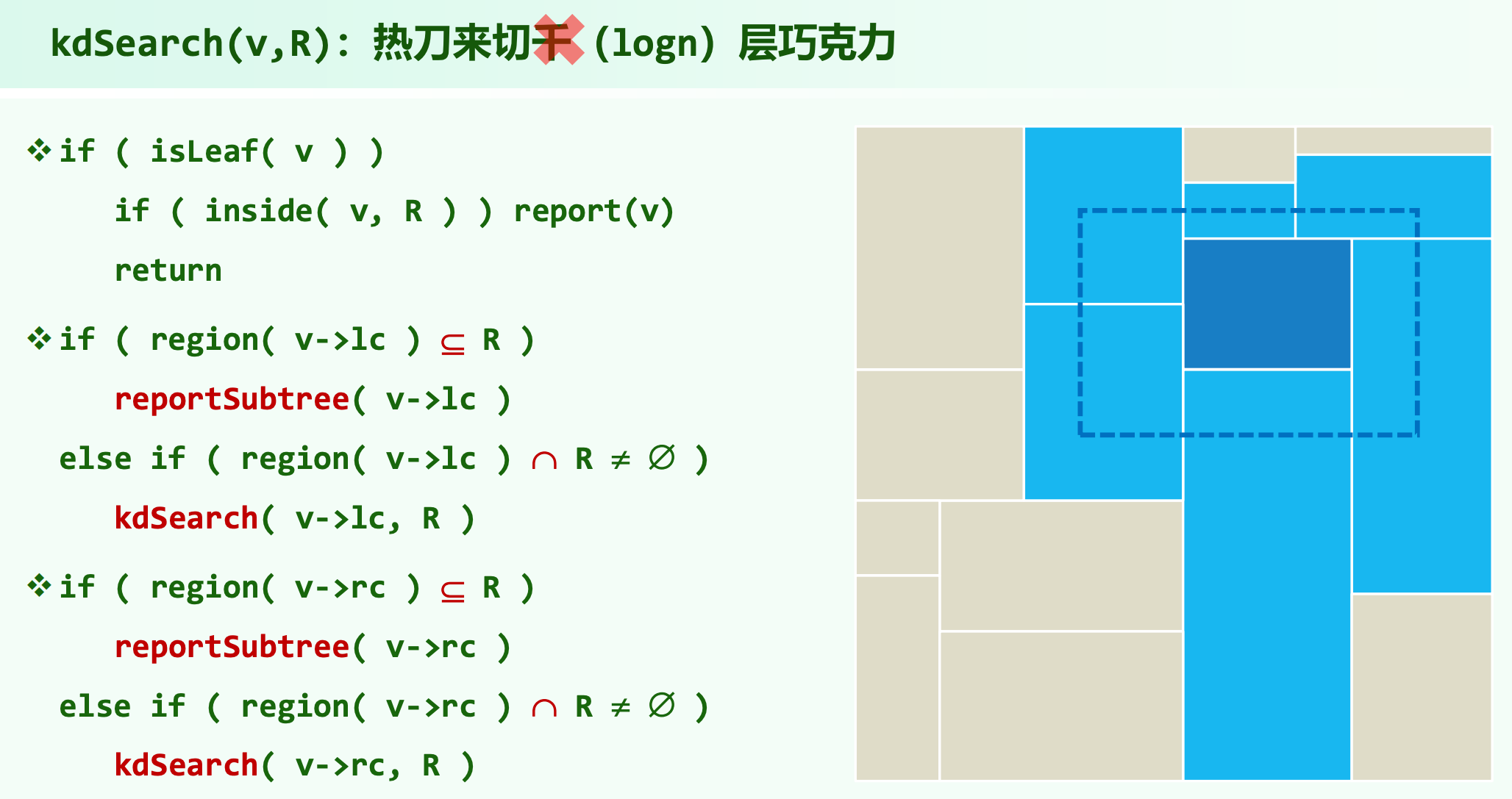
对该搜索算法的每一行逻辑判断与几何检验进行深刻剖析: 算法首先处理递归的最底层。当探测指针深入至叶子节点时(isLeaf(v)),系统退化为最基本的代数坐标比较。通过调用 inside(v, R) 判定该单一数据点是否落入查询范围内部,若是则触发 report(v) 输出结果,随后终止当前路径的递归(return)。
对于内部节点,算法展开了极具智慧的几何相交测试与子树剪枝。针对节点的左子树(v->lc),算法首先进行全包含判定。如果在几何上,左子树所代表的矩形空间被完全包裹在查询区域 内部(),此时该左子树构成了一个完美的规范子集。算法将直接调用 reportSubtree(v->lc) 函数,以极高的吞吐量将该子树挂载的所有叶子节点整体输出,而彻底放弃对该分支更深层次的探查 。 若全包含判定失败,算法退而求其次进行边缘相交测试。如果左子树区域虽然未被全包围,但其边界与查询范围 存在几何重叠(),则表明有一部分目标数据可能隐藏在该子树的深处。此时系统被迫递归调用 kdSearch(v->lc, R) 深入下一层继续进行“热刀裁剪”。如果交集为空(),则触发无声的剪枝机制,该子树被系统永久抛弃。 随后,算法对右子树(v->rc)执行完全对称的 判定以及 相交测试逻辑 。
通过分析这一算法,可以严谨推导出 KD 树二维范围查询的时间复杂度为 。其数学论证如下:查询耗时的核心瓶颈在于算法必须递归访问那些边界被查询矩形 的边框“切过”的区域节点 。考虑矩形边界的任一条垂直线,它将穿透多少个内部节点的区域?在 KD 树中,由于切分维度在每一层交替,假设根节点进行垂直切割,其两个子节点则进行水平切割。在向下深入两层的过程中,空间被横纵两刀切分为四个包含 个数据点的子区域。由于测试边界是一条垂直线,它最多只能穿过这四个子区域中的两个 。由此,我们可以写出边界线穿过的区域数量 的数学递归方程:
应用算法分析中的主定理,在此方程中 ,其解析解为 。考虑到矩形 由四条边构成,相交节点的总数上限仍为 。再加上通过 reportSubtree 收集并输出 个结果节点所需要的线性时间,二维情况下的最终复杂度被严格证明为 。推广至更高维度的超空间,对于 维的范围查询,其复杂度在最坏情况下收敛于 。
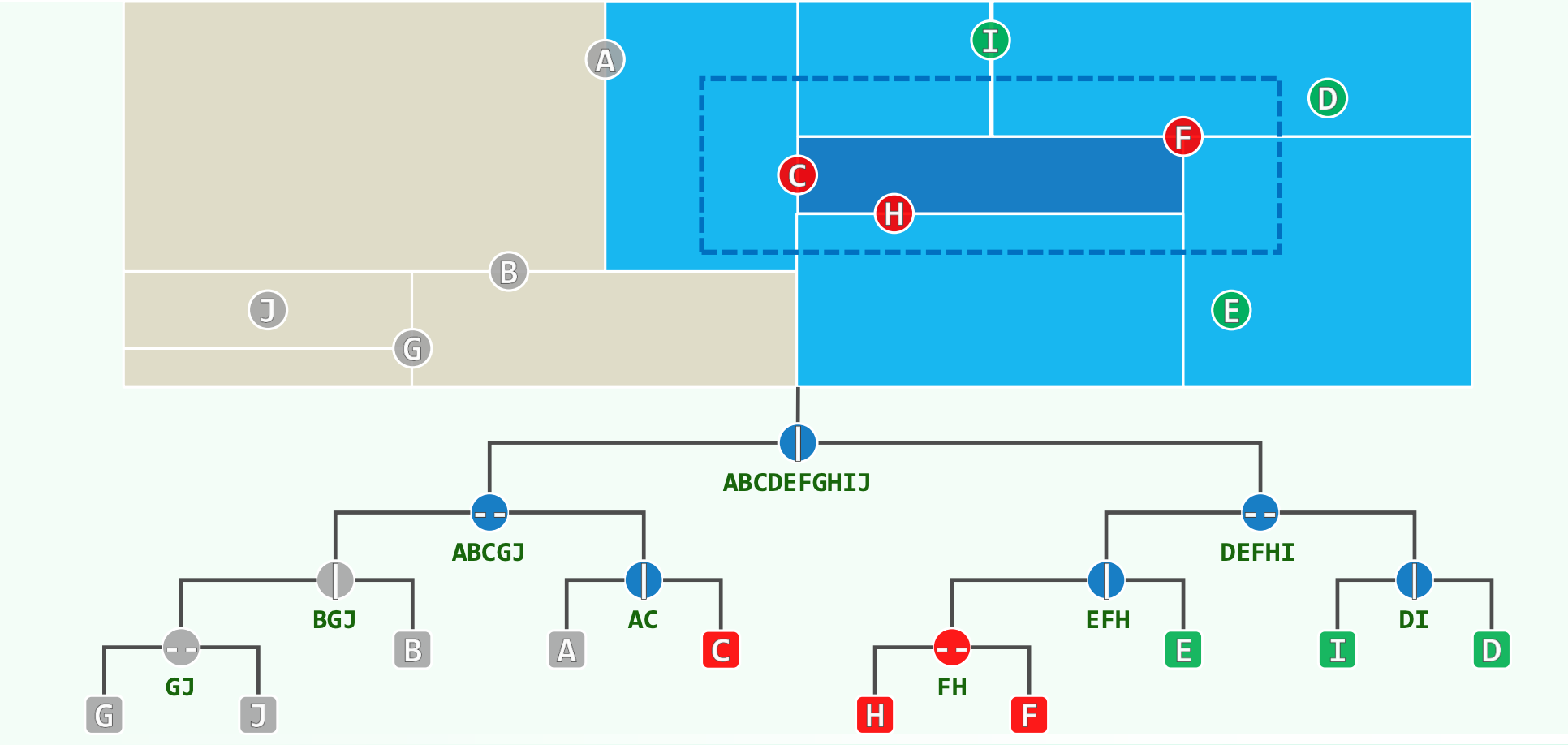
将递归逻辑映射到包含节点 A 至 J 的拓扑图中,算法的执行轨迹显现出极强的目的性。当算法启动时,首先评估包含全集 ABCDEFGHIJ 的根节点空间。如果该全空间仅部分与目标范围重叠,算法将视线转移至子集 ABCGJ 和 DEFHI。
算法先查看左子树的ABCGJ:
- 它的左子树划分出的区域
BGJ与搜索区域明显没有交集,所以可以直接剪枝掉。 - 它的右子树划分的区域与查询区域相交,于是算法对其中的点分别评估,丢弃掉不在查询范围内的
A,然后将处于查询范围内的C输出。
接下来查看右子树划分出的区域DEFHI:
- 它的左子树为
EFH,这个区域和查询范围是相交的,所以算法进一步深入查询,发现左子树FH完全被查询集合包含,于是直接将这个子树输出,而右子树中的一个点E并不在查询范围内并将其丢弃。 - 右子树
DI由于也与查询范围相交,于是对其中的两个点分别评估,得出不在查询范围内并丢弃。
Bounding Box
为了使得几何相交测试 region(v) ∩ R 和包含测试 region(v) ⊆ R 在极短的 CPU 时钟周期内完成,KD 树的内部节点往往需要隐式或显式地维护其边界框属性 。边界框通常通过一个最小和最大的多维坐标向量(Min, Max)来极简地表示当前区域在整个空间中的绝对极限。在进行 kdSearch 时,只需对比查询矩形与节点边界框的端点坐标,而无需进行复杂的几何多边形碰撞检测运算,这进一步压榨了硬件的指令执行效率,本质上是牺牲空间换执行效率。
应用-最近邻搜索
NN 搜索算法
除了范围查询,最近邻搜索(Nearest-Neighbor search, NNS)是 KD 树最为核心且应用最为广泛的高级检索功能,旨在浩瀚的高维数据海中,迅速寻找与目标查询点在欧氏距离上最接近的一个或多个样本点 。在数据分布均匀的低维空间中,NNS 的经验平均时间复杂度能够惊人地维持在 级别 。然而,要实现这一性能,必须依赖一套极为巧妙的超球面构建与回溯剪枝方法 。
最近邻搜索的执行过程是一个典型的深度优先下探与回溯验证的组合,其核心步骤详细拆解如下:
在第一阶段,算法对几何空间进行基于坐标轴的快速试探。目标查询点被投喂进入 KD 树的根节点。此时,算法根据节点所在层级的交替分割方向(X-Splitting planes 或者 Y-Splitting planes,对于叶子节点则不需要切分面),将目标点坐标与节点分割面进行逐级比对 。算法采用贪心策略,一路向目标点可能所处的空间分支疾驰,直至抵达最底层的某个叶子节点 。
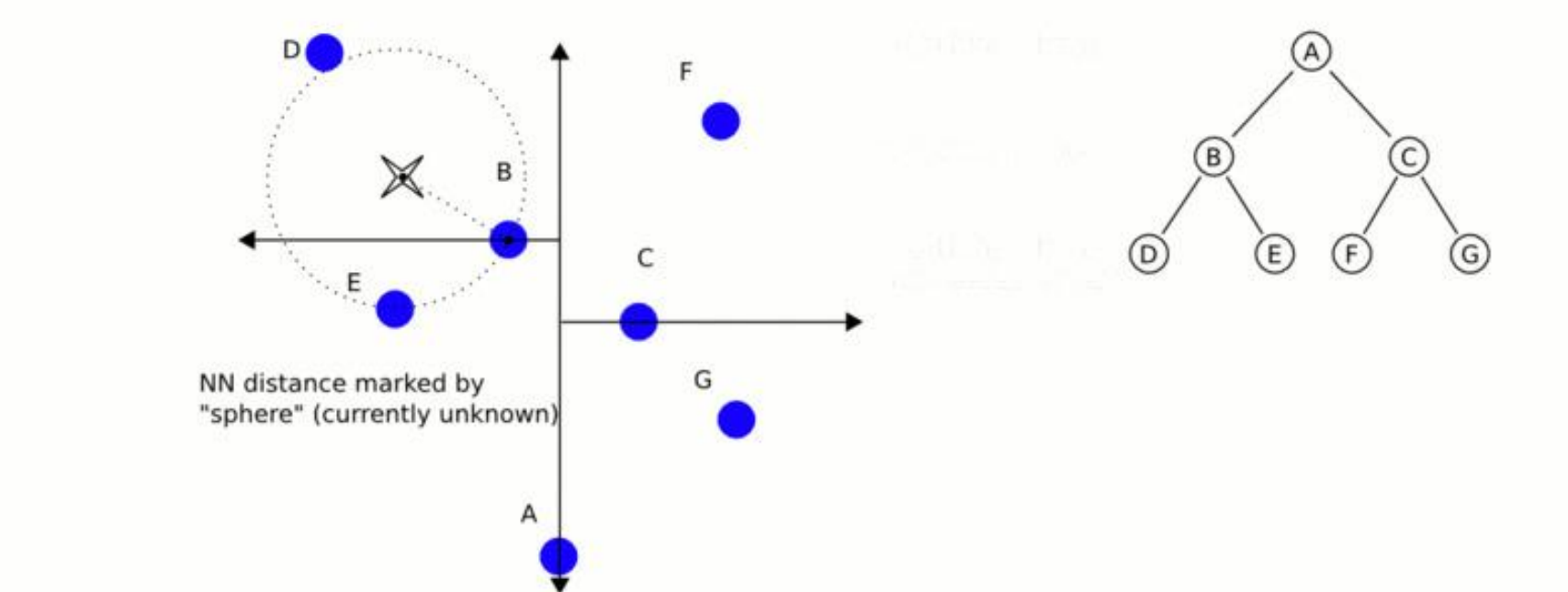
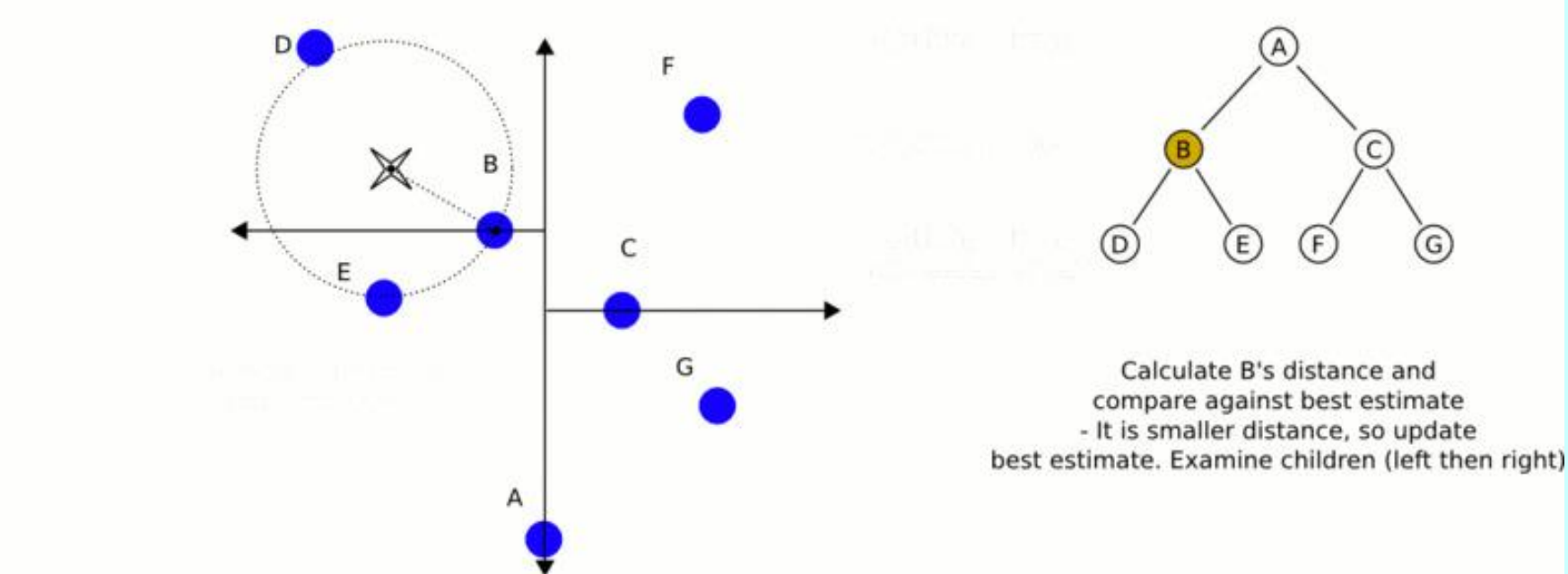
到达叶子节点后,进入第二阶段。该叶子节点被算法标记为“当前最佳估计”。算法计算目标点与该叶子节点之间的几何距离,并以此距离作为半径,以目标点为圆心,在多维空间中膨胀出一个虚拟的 N 维超球面。在搜索的初始阶段,真正的最近邻可能尚未被发现,这个超球面的作用就是划定一个可能存在更优解的空间上限边界。
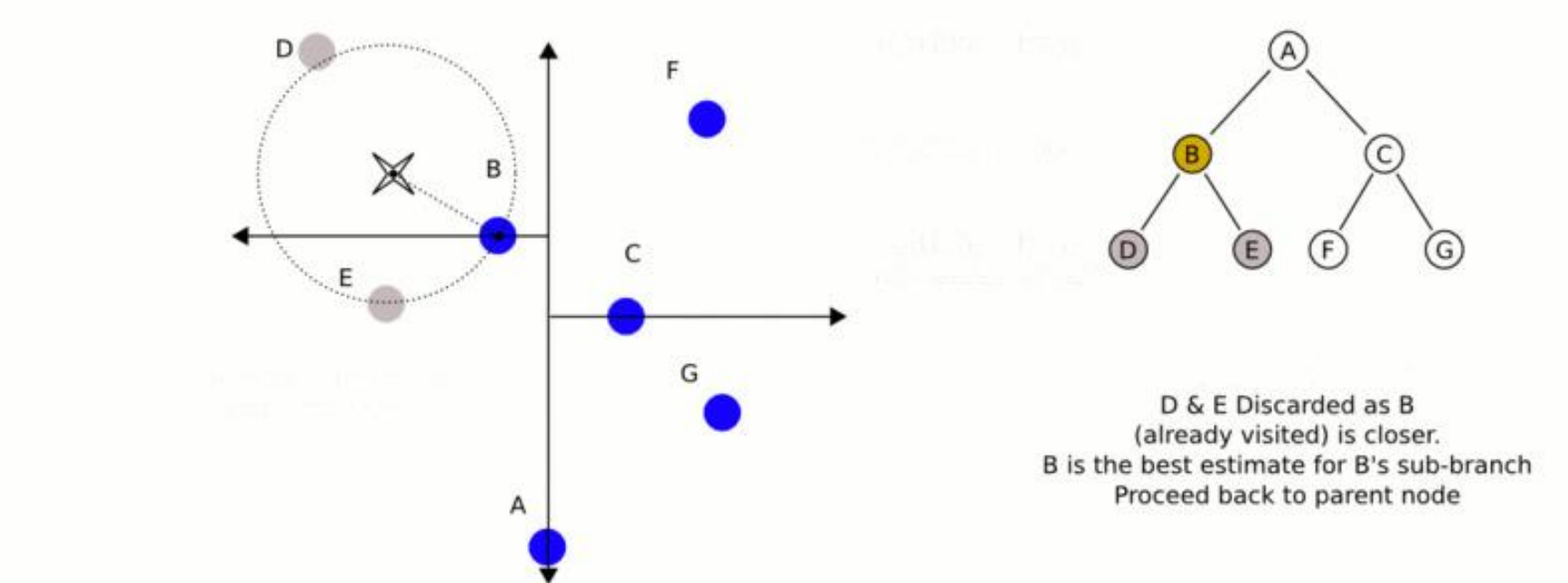
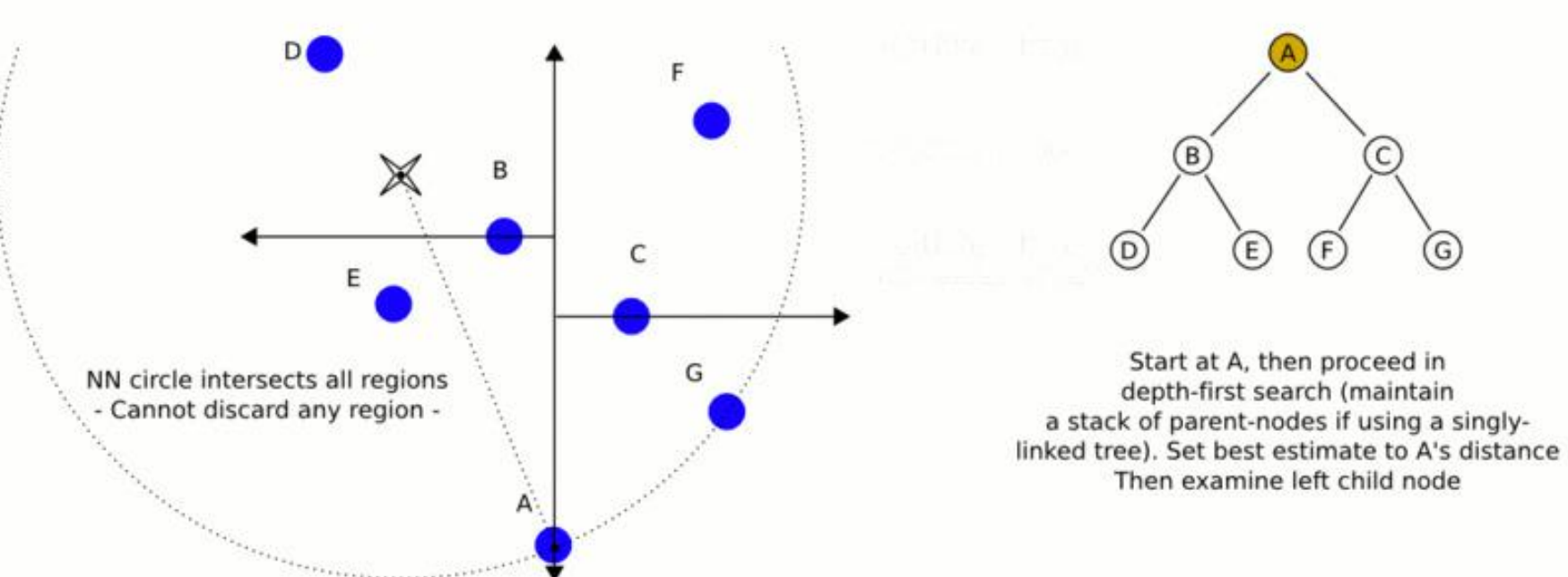
第三阶段是最为复杂的回溯与几何相交排查阶段。算法开始沿着原先深度优先下探的路径向父节点逐级返回。在退回至每一个父节点时,算法执行以下连串逻辑:
- 首先,检查父节点自身是否落入超球面内,即父节点与目标点的距离是否小于“当前最佳估计”。若是,则更新最佳估计节点,并相应地收缩超球面的半径。
- 其次,是最关键的跨分支相交测试。在父节点处,不仅要检查该节点自身,还要评估是否需要深入父节点的另一侧子分支(即先前下探时判定为方向不符而跳过的那一半树)。判定标准是:计算目标点到父节点所代表的分割超平面的垂直法向距离。 如果该垂直距离小于当前超球面的半径,意味着超球面的体积已经穿透了该分割平面,侵入了另一侧的子空间。这在几何上表明,另一侧子树中完全有可能潜伏着一个距离目标点更近的节点。
- 此时,算法被迫无法抛弃该区域,必须强制进入另一侧子树,并对其重新执行深度优先与回溯的探索。 反之,如果垂直距离大于或等于超球面的半径,这意味着超球面的边界根本触碰不到父节点的分割面。在拓扑上,另一侧子树的任何节点都不可能比“当前最佳估计”更近,因为它们全部被隔离在分割面的远端。由于这种几何上的绝对互斥,算法触发强制剪枝机制,另一侧整个庞大的子树结构被瞬间丢弃,系统直接继续向更上层的祖先节点回溯 。
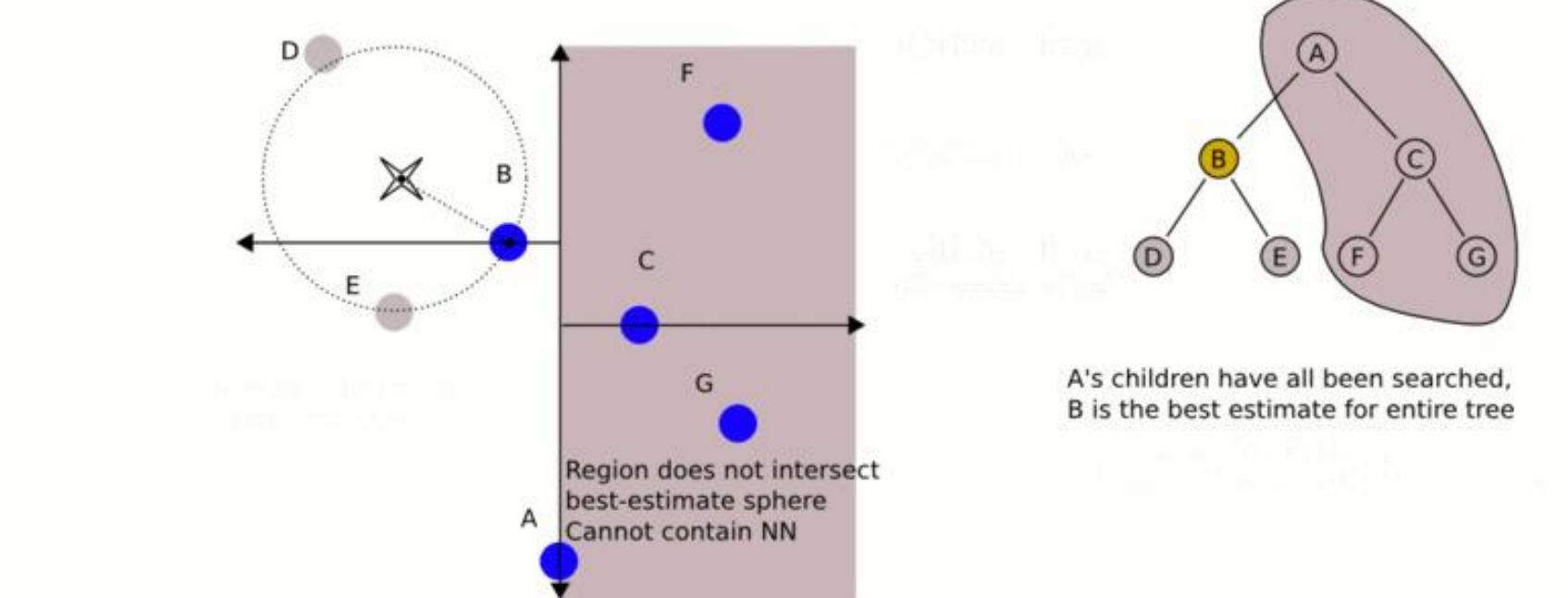
通过这种利用距离收敛动态收缩超球面,并结合法向距离进行大面积空间摒弃的机制,KD 树成功将原本 的暴力距离计算,压缩至对数级别的时间消耗。
算法的工程实现
在现代计算硬件平台(如依赖深度并行管线的 GPU 或受限于指令堆栈的嵌入式系统)上,KD 树的标准递归搜索会遭遇严重的性能瓶颈。高维度的回溯很容易引发过深的函数调用链,导致栈内存溢出或缓存命中率暴跌 。为了在工程底层压榨极致性能,NNS 的实现通常抛弃原生的函数递归,转而采用一种基于显式栈管理的两阶段非递归搜索架构。
在这一高级实现方案中,底层的数据结构通常被定义如下,不仅包含指向左右子树的内存指针,还需要显式存储当前节点负责切分的维度标识:
1 | struct KDNode { |
基于显式栈的高性能搜索架构被精细地划分为三个运算流水线阶段:
第一阶段:内存与状态初始化 系统必须在堆或者预分配的内存池中创建一个显式的、用于追踪回溯路径的空指针栈 search_stack。同时,设定一个追踪全局最小距离的寄存器变量,并将其初始值设定为系统所支持的最大浮点数,用于记录的最近邻节点指针初始化为空指针。
第二阶段:贪心深度优先下探 通过 while 循环取代递归。算法沿着目标点在多维空间中的理论收敛路径直达叶子节点。在这个循环推进的过程中,每一颗被访问的内部节点都必须立即被压入显式栈中(search_stack.push(current);)。在下探的同时,算法可选择性地实时计算当前节点与目标点的距离并更新最近邻寄存器,以此在早期快速获取一个质量尚可的局部最优解 。
第三阶段:回溯与超球面裁剪 当探底完成后,系统开始持续从栈顶弹出节点进行自底向上的逆向验证,这也是显式栈架构的精髓所在 。其伪代码控制流如下:
1 | while (!search_stack.empty()) { |
在不断的 pop 弹栈循环中,对于提取出的每一个 node,算法会提取其 axis 属性,并极其高效地仅进行一次一维的标量减法运算,得出目标点到该 node 所定义的分割面的垂直距离。倘若该标量距离绝对值小于目前登记的最近几何距离,这意味着当前收敛的超球面与被弹出的父节点分割面发生了干涉,另一侧的分支(先前未压栈的一侧)暴露在可能包含更优解的风险中 。此时,控制流将发生跳转,算法捕获另一侧子树的根指针,并对其重新调用第二阶段的 while 循环下探逻辑,将沿途节点追加至栈中 。若垂直距离未能突破超球面,则证明另一侧空间绝对安全,控制流无视另一侧子树,继续执行下一轮弹栈。直至栈被彻底清空,寄存器中缓存的节点即为全局欧氏空间中的绝对最近邻 。这一设计彻底解耦了算法逻辑与系统调用堆栈,为极高频的大规模点云检索铺平了硬件执行道路。
KD Tree 用途
随着计算机性能的飞跃,这种构建于上世纪 70 年代的基础数据结构非但没有被历史淘汰,反而在现代人工智能、计算机视觉与机器人自主导航领域展现出了惊人的生命力。KD 树在以下两个高精尖应用场景中扮演着不可或缺的基石角色 。
SIFT 算法特征点匹配与高维优化
在计算机视觉的图像识别与全景拼接任务中,尺度不变特征变换(Scale-Invariant Feature Transform, SIFT)是一种通过分析图像在多尺度空间中极值点,从而提取出对旋转、缩放、亮度变化保持极强鲁棒性的局部特征描述子算法 。SIFT 算法最终会将每一个检测到的视觉特征点编码为一个 128 维的高维特征矢量。当系统在包含数百万特征的巨大数据库中进行特征匹配时,本质上是在一个 128 维的几何空间内执行海量的相似性最近邻查询。
然而,当空间维度攀升至 10 到 20 维以上时,标准的 KD 树架构会遭遇严重数学危机——维度灾难。在 128 维的极高维空间中,数据点散布得极其稀疏。在进行 search_stack 回溯验证时,由于维度的累加效应,目标点到绝大多数分割面的欧氏法向距离,几乎总是小于它与“当前最佳估计”的距离。这导致前文所述的“剪枝机制”近乎失效,超球面无休止地切过各种超平面,算法被迫陷入永无止境的跨分支探查,搜索性能惨烈退化至与暴力搜索相同的 级别 。
为了攻克这一致命瓶颈,学术界基于 KD 树开发了改良版的最佳优先搜索算法(Best Bin First, BBF)。BBF 算法彻底颠覆了 KD 树原有的严格深度优先回溯路径。它通过引入优先队列,将所有尚未被探查的分割面依据其与目标点的距离进行升序排列。算法不再拘泥于树的几何拓扑,而是永远优先弹出并探索距离目标点最近的空间分区。配合人为设定的最大搜索次数上限(阈值中断),BBF 算法巧妙地放弃了寻找数学上绝对精确的最近邻,转而以微小的精度损失,换取了在极高维特征向量空间下的实时近似最近邻(Approximate Nearest Neighbor, ANN)检索能力,从而真正促成了 SIFT 匹配在工业界的落地应用 。
激光雷达 SLAM 三维点云配准
在面向自动驾驶与移动机器人的前沿研究中,同步定位与建图(Simultaneous Localization and Mapping, SLAM)高度依赖于车辆顶部搭载的 3D 激光雷达(LiDAR)传感器 。激光雷达通过发射大量高频脉冲,能够瞬间扫描周遭的地理环境,生成包含海量三维坐标信息的点云。
在 LiDAR SLAM 框架的前端里程计中,最关键的核心步骤是估算连续两帧激光扫描之间的自身位姿移动。这通过一种被称为点云配准的数学技术实现 。工业界最普遍采用的方法是迭代最近点算法。ICP 算法试图在当前扫描的源点云与上一帧或全局地图的目标点云之间建立几何对应关系,进而通过 SVD 分解或高斯-牛顿等最优化方法,求解出最佳的旋转与平移变换矩阵 。
然而,点云规模通常极为庞大,ICP 算法的性能瓶颈完全集中在其“寻找对应点”这一操作上 。如果采用暴力距离计算,ICP 的每一次迭代都将耗费灾难性的时间。为此,现代 SLAM 系统无一例外地依赖于 KD 树结构 。在相对低维(通常为 3 维 XYZ 坐标)的真实物理空间中,KD 树没有维度灾难的困扰,其边界框剪枝机制能够完美发挥效能,将点到点的暴力检索耗时从 极限压缩至 级别 。无论是执行用于提取道路轮廓的范围查询,还是在 ICP 配对环节执行 K近邻查询(K-neighbor searches),KD 树都是维系自动驾驶系统实时处理帧率的底层算法心脏。近年来,针对 SLAM 动态建图的需求,基于 KD 树演化而来的增量式结构(如 ikd-Tree)更是允许系统在无需全局重建的条件下动态插入新地图特征,进一步将响应延迟推向了新的极限 。