将数据向量化
生成模型通常将不同模态的数据统一表示为高维欧几里得空间中的向量,从而使用微积分、线性代数和概率论进行建模。
| 模态 |
表示 |
意义 |
| 图像 |
z∈RH×W×3 |
高度为 H、宽度为 W,每个像素包含 RGB 三个连续强度值。 |
| 视频 |
z∈RT×H×W×3 |
在图像空间维度外增加 T 个时间帧。 |
| 分子结构 |
z∈R3×N |
包含 N 个原子的三维坐标,可表示为矩阵或展平向量。 |
所有生成对象都可抽象为实值向量 z∈Rd。这种表示忽略模态差异,保留可计算的连续空间结构。
传统文本通常建模为离散 token;离散扩散模型则尝试用连续时间马尔可夫链处理文本生成。
基于概率分布采样的生成
预测模型通常输出确定性答案;生成模型需要刻画数据的多样性,因此更适合以概率分布描述。
生成模型将数据空间 Rd 上的真实样本看作来自概率分布 pdata。在连续空间中,pdata 是概率密度函数:
pdata:Rd→R≥0
它为每个可能对象 z 分配非负密度 pdata(z)。若 z 对应的图像更符合真实数据分布,其密度更高。
生成等价于从未知分布 pdata 中采样 z∼pdata。由于无法获得 pdata 的解析形式,训练只能依赖有限的独立同分布样本:
z1,...,zN∼pdata
生成模型的目标是利用有限样本近似底层数据分布,并从中生成新样本。
条件引导生成
实际应用通常要求模型按条件 y 生成样本,例如按文本生成图像。这等价于从条件分布 pdata(⋅∣y) 采样,训练数据也从单独样本变为成对数据 (z1,y1),...,(zN,yN)。
条件生成的关键是泛化:模型不仅要拟合训练集中出现过的条件,还要处理未见过的语义组合。无条件生成中的 ODE/SDE 框架可以自然扩展到条件生成。
流模型
将生成问题写成从 pdata 采样后,核心问题变成如何在高维空间中实现采样。传统 MCMC 方法在百万维图像空间中收敛困难。
流模型和扩散模型通过动力学系统完成采样:从易采样的先验分布出发,逐步演化到目标数据分布 pdata。确定性演化通常由 ODE 描述,随机演化由 SDE 描述。
定义
ODE 的解 X 是状态空间中的确定性演化轨迹:
X:→Rd,t↦Xt
轨迹由向量场 u 驱动。向量场给出每个位置和时刻的速度:
u:Rd×→Rd,(x,t)↦ut(x)
ODE 描述向量场驱动的轨迹演化:
dtdXt=ut(Xt)(ODE)
X0=x0(初始条件)
给定初始位置 X0=x0,流映射 ψ 将 x0 映射到时间 t 的位置 Xt:
ψ:Rd×→Rd,(x0,t)↦ψt(x0)(流映射)
dtdψt(x0)=ut(ψt(x0))(流 ODE)
ψ0(x0)=x0(流初始条件)
给定初始条件后,轨迹可由流映射恢复:Xt=ψt(X0)。向量场给出局部速度,ODE 给出微分约束,流是该约束的全局积分解。
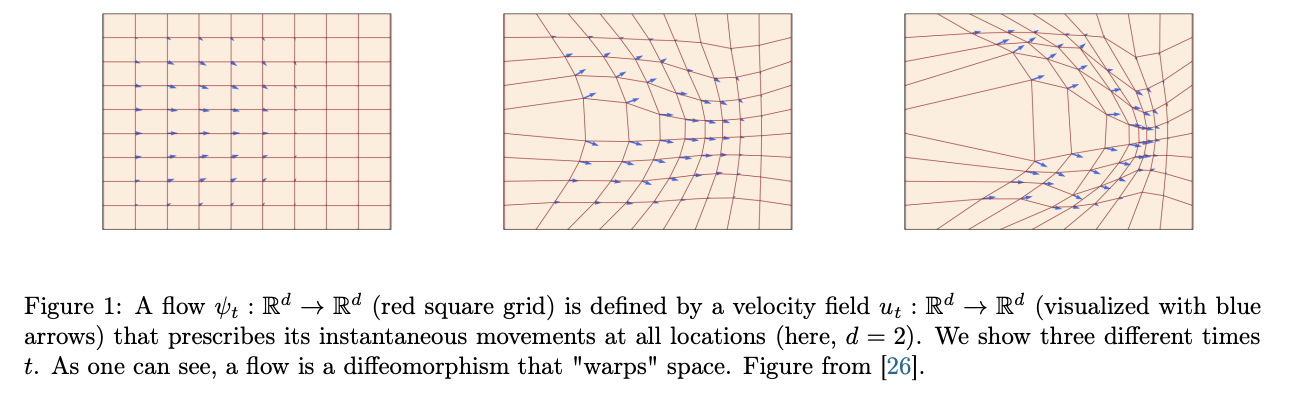
流的存在性与唯一性:若向量场 u:Rd×[0,1]→Rd 连续可微且导数全局有界,则 ODE 存在唯一解。在该条件下,ψt 是微分同胚,ψt 与逆映射 ψt−1 都连续可微。
机器学习中通常用神经网络参数化 ut(x)。在常见正则化和有限计算域下,可将其视为满足稳定求解所需的光滑性条件。
ODE 的数值方法模拟
实际流模型通常没有解析解,需要数值积分。欧拉法将连续时间离散为迭代更新:
Xt+h=Xt+hut(Xt)对于离散时间步(t=0,h,2h,3h,...,1−h)
h=n−1其中模拟步数n∈N
为减少推理步数并提高精度,可使用高阶积分方法。休恩方法是一种预测-校正算法:
Xt+h′=Xt+hut(Xt)使用经典欧拉法对新状态进行初步的线性预测
Xt+h=Xt+2h(ut(Xt)+ut+h(Xt+h′))利用当前与预测状态下向量场的平均值进行校正
休恩方法利用预测点处的向量场校正一阶欧拉误差,通常比欧拉法更稳定。
流模型 & ODE
ODE 流模型将未知向量场 ut 参数化为神经网络 utθ:Rd×→Rd。
生成任务需要从 pdata 采样。ODE 演化本身是确定性的,因此多样性必须来自随机初始条件。
因此先从易采样的初始噪声分布 pinit 采样,常取 pinit=N(0,Id)。生成流程包括:
- 随机初始化:X0∼pinit
- ODE 演化:利用神经网络预测的瞬时速度,沿着向量场进行数值积分:dtdXt=utθ(Xt)。
训练目标是学习向量场,使终点分布在 t=1 时匹配真实数据分布:
X1∼pdata⟺ψ1θ(X0)∼pdata
注意:模型输出的是局部向量场,而不是直接输出最终样本。采样时仍需通过数值积分求解 ODE。

扩散模型
扩散模型在流模型的确定性演化基础上引入 SDE。SDE 轨迹不再由初始点唯一决定,而是受到连续随机扰动影响。
SDE 将生成过程刻画为随机过程 (Xt)0≤t≤1,主要特征如下:
- X:→Rd 的演化不再是单值对应。
- 对于每一个被固定的时间截面 0≤t≤1,Xt 都不再是一个具体的空间点,而是一个具有特定空间概率分布的随机变量。
- 对于给定的同一个初始起点 X0,针对随机过程 X 的每一次“抽取”,其映射路径 t↦Xt 都会在多维空间中生成一条截然不同、具有极高复杂度的随机轨迹。
因此,即使初始点、模型参数和步长相同,两次 SDE 模拟也可能得到不同终点。
布朗运动
SDE 的随机项通常由布朗运动给出。标准 d 维布朗运动也称 Wiener Process,记作 W=(Wt)0≤t≤1,满足:
- W0=0,且样本路径 t↦Wt 连续。
- 对 0≤s<t,增量满足 Wt−Ws∼N(0,(t−s)Id)。
- 不相交时间区间上的增量相互独立。
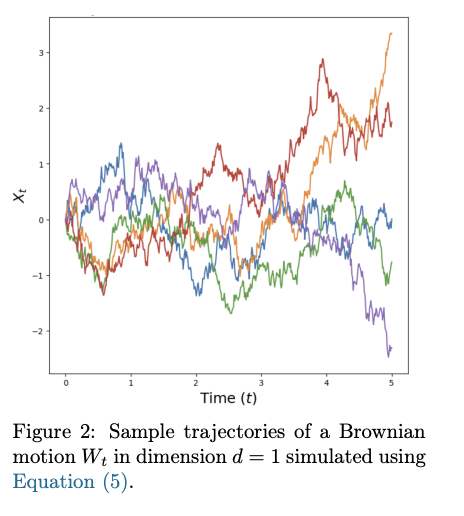
布朗运动路径连续但处处不可微,在任意小区间内总变差无穷大。因此不能直接使用经典微积分处理 dWt/dt,需要伊藤微积分等随机微积分工具。
时间离散化后,可用如下更新近似布朗运动。给定步长 h>0,从 W0=0 出发:
Wt+h=Wt+hϵt,其中ϵt∼N(0,Id)对于离散时间点(t=0,h,2h,...,1−h)
噪声缩放系数是 h,因为长度为 h 的布朗增量方差应为 hId。
从 ODE 到 SDE
SDE 可看作在 ODE 漂移项上加入布朗扰动。由于布朗运动处处不可微,不能直接使用经典导数形式,需要用小时间增量定义。
先将 ODE 写成离散增量形式:
dtdXt=ut(Xt)(原始导数形式)
h1(Xt+h−Xt)=ut(Xt)+Rt(h)(通过导数极限定义转化)
Xt+h=Xt+确定性主导项hut(Xt)+高阶截断误差项hRt(h)
其中 Rt(h) 是随 h→0 消失的高阶误差。该式对应欧拉法:每一步沿 ut(Xt) 移动 h 倍速度。
加入布朗扰动后,SDE 的增量形式为:
Xt+h=Xt+确定性漂移分量hut(Xt)+布朗随机波动分量σt(Wt+h−Wt)+可忽略的高阶误差项Rt(h)
其中 σt≥0 是扩散系数,控制随机噪声强度;Rt(h) 表示离散化误差。
取 h→0 后,得到 SDE 的常用符号形式:
dXt=ut(Xt)dt+σtdWt(SDE 核心符号方程)
X0=x0(初始条件)
由于 Wt 不可微,dWt 不能按普通微分做代数除法或移项,只能在随机微积分语义下理解。
SDE 不再定义确定性流映射;同一初始点也会因随机增量产生不同路径。但在常见光滑性条件下,SDE 仍有强解的存在性与唯一性:
SDE 强解的存在性与唯一性:若漂移向量场 u:Rd×→Rd 对状态变量连续可微且偏导数全局有界,扩散系数 σt 关于时间连续,则该 SDE 存在唯一强解,即满足上述增量性质的随机过程 (Xt)0≤t≤1。
ODE 是 SDE 的特例:令 σt≡0 即可退化为确定性动力学。因此 SDE 框架包含 ODE 流模型。
SDE 的数值方法模拟
SDE 通常也需要数值模拟。Euler-Maruyama 方法是欧拉法在随机微分方程中的对应形式。
将时间区间切分为步长 h=n−1,给定初始状态 X0=x0,每步更新为:
Xt+h=Xt+hut(Xt)+hσtϵt,其中每一时间步必须重新独立采样ϵt∼N(0,Id)
该更新包含两部分:hut(Xt) 是确定性漂移,hσtϵt 是随机扩散项。每个时间步都重新采样独立噪声。
扩散模型 & SDE
扩散模型用 SDE 描述从先验分布到数据分布的随机演化过程。
与 ODE 流模型类似,扩散模型从 X0∼pinit 出发,用神经网络参数化漂移向量场 ut。
参数化后得到 utθ,扩散生成过程可写为:
X0∼pinit(启动阶段的随机初始化操作)
dXt=utθ(Xt)dt+σtdWt(驱动生成过程的核心 SDE 机制)
推理时可用 Euler-Maruyama 方法离散求解该 SDE,并从终点获得样本。






