Guidance
前面讨论的是无条件生成,即从 pdata(z) 采样。实际应用通常需要按 prompt 或其他信息生成特定样本,这类额外信息称为 Guidance。
Vanilla Guidance
最直接的方法是在训练和推理阶段将条件变量 y 输入神经网络,学习条件向量场 utθ(⋅∣y)。
定义
基础引导式扩散/流模型由条件神经网络向量场和时间扩散系数 σt 定义:
- 神经网络定义:uθ:Rd×Y×[0,1]→Rd,(x,y,t)↦utθ(x∣y)。输入为带噪状态 x、条件 y 和时间 t,输出 d 维去噪方向。
- 固定扩散系数:σt:[0,1]→[0,+∞)t↦σt
采样步骤
- 初始化:从先验分布采样 X0∼pinit,通常为 N(0,Id)。
- 微分方程模拟:从 t=0 积分到 t=1,模拟 dXt=utθ(Xt∣y)dt+σtdWt。其中 σt=0 时退化为 ODE 流模型。
- 优化目标:终点满足 X1∼pdata(⋅∣y)。
流匹配目标
训练条件网络 utθ(x∣y) 时,真实数据来自联合分布 pdata(z,y),目标是学习 pdata(x∣y)。
对应的 Guided Conditional Flow Matching Objective 为:
LCFMtarget(θ)=E(z,y)∼pdata(z,y),t∼Unif,x∼pt(⋅∣z)∥utθ(x∣y)−uttarget(x∣z)∥2
各项含义:
- 联合分布采样 (z,y)∼pdata(z,y):采样真实样本及其条件。
- 时间采样 t∼Unif:随机采样时间步。
- 状态采样 x∼pt(⋅∣z):按条件路径生成中间带噪状态。
- 回归目标:在给定 x,y 时预测 uttarget(x∣z)。条件 y 不改变 pt(⋅∣z),只作为神经网络上下文输入。
Vanilla Guidance 的局限
理论上,充分数据和模型容量可使 Vanilla Guidance 学到 pdata(⋅∣y)。实际中,生成结果常与提示词契合不足。

主要原因:
- 高维条件信号稀释:图像空间维度高,文本条件信号容易被通用视觉特征淹没。
- 数据质量缺陷与错配:现实世界中的图文对存在大量的噪声、描述不全或错误匹配。这种弱监督信号导致模型无法建立 y 与特定视觉特征之间的强对应关系。
- 决策边界模糊:高噪声阶段不同条件的分布重叠,基础模型缺少显式放大条件差异的机制。
因此需要在采样阶段放大条件信号,即 Classifier Guidance 和 Classifier-Free Guidance。
Classifier Guidance
Classifier Guidance 使用额外分类器在采样阶段修正生成方向。下面以高斯概率路径说明其分数函数推导。
向量场与分数函数的等价转换
在条件高斯路径 pt(⋅∣z)=N(αtz,βt2Id) 下,向量场和分数函数存在线性关系:
uttarget(x∣y)=at∇logpt(x∣y)+btx
系数为:
- 比例系数 at:定义为 at=(βt2αtα˙t−β˙tβt)。
- 偏移系数 bt:定义为 bt=αtα˙t。
- 导数:α˙t 和 β˙t 是噪声调度函数对时间 t 的一阶导数。
该关系说明:给定 t,x 后,条件向量场由条件分数 ∇logpt(x∣y) 决定。
解耦条件分数
根据贝叶斯公式,条件分数可分解为:
pt(x∣y)=pt(y)pt(x)pt(y∣x)
对两边取对数并对 x 求梯度:
∇logpt(x∣y)=∇log(pt(y)pt(x)pt(y∣x))=∇logpt(x)+∇logpt(y∣x)−∇logpt(y)
因为 pt(y) 与 x 无关,最后一项为 0:
∇logpt(x∣y)=∇logpt(x)+∇logpt(y∣x)
条件分数被分解为:
- 无条件分数 ∇logpt(x):保证样本落在真实数据分布上。
- 似然梯度 ∇logpt(y∣x):由分类器给出,推动样本更符合条件 y。
构建与放大分类器引导向量场
代回向量场线性关系:
uttarget(x∣y)=btx+at(∇logpt(x)+∇logpt(y∣x))=无条件向量场 uttarget(x)(btx+at∇logpt(x))+at∇logpt(y∣x)=uttarget(x)+at∇logpt(y∣x)
条件向量场等于无条件向量场加上分类器似然梯度项。
为增强条件对齐,引入 Guidance Scale w,将分类器梯度放大为 wat∇logpt(y∣x):
u~t(x∣y)=uttarget(x)+wat∇logpt(y∣x)(Classifier Guidance)
增大 w 可增强条件对齐。
分类器引导的局限
分类器引导的工程问题:
- 额外模型依赖:需要独立分类器估算 pt(y∣x),增加复杂度和显存压力。
- 噪声分类困难:采样早期 xt 接近高斯噪声,普通分类器不能直接使用,需要训练噪声感知分类器。
- 开放文本条件困难:自由文本条件难以用传统分类器稳定建模。
因此引入无分类器引导(CFG)。
Classifier-Free Guidance
CFG 在不依赖外部分类器的情况下,实现与分类器引导类似的条件放大效果。
消除额外分类器的依赖
使用前面的贝叶斯分解:
∇logpt(x∣y)=∇logpt(x)+∇logpt(y∣x)
条件分数可由条件生成模型预测,无条件分数可由无条件生成模型预测。因此分类器梯度可写为二者差值:
∇logpt(y∣x)=∇logpt(x∣y)−∇logpt(x)
条件模型与无条件模型的差值可看作隐式分类器梯度。
代回带放大因子 w 的引导公式:
u~t(x∣y)=uttarget(x)+wat∇logpt(y∣x)=uttarget(x)+wat(隐式分类器梯度∇logpt(x∣y)−∇logpt(x))
利用 at∇logpt(x)=uttarget(x)−btx 及条件版本,化简为:
u~t(x∣y)=uttarget(x)−w(btx+at∇logpt(x))+w(btx+at∇logpt(x∣y))=uttarget(x)−wuttarget(x)+wuttarget(x∣y)=(1−w)uttarget(x)+wuttarget(x∣y)
得到 CFG 核心公式:
u~t(x∣y)=(1−w)uttarget(x)+wuttarget(x∣y)
用 ∅ 表示无条件输入:
u~t(x∣y)=(1−w)uttarget(x∣∅)+wuttarget(x∣y)
因此可以用同一个模型同时处理有条件和无条件输入,无需额外分类器。
为何 CFG 表现优秀?
CFG 是条件输出相对无条件输出的线性外推。
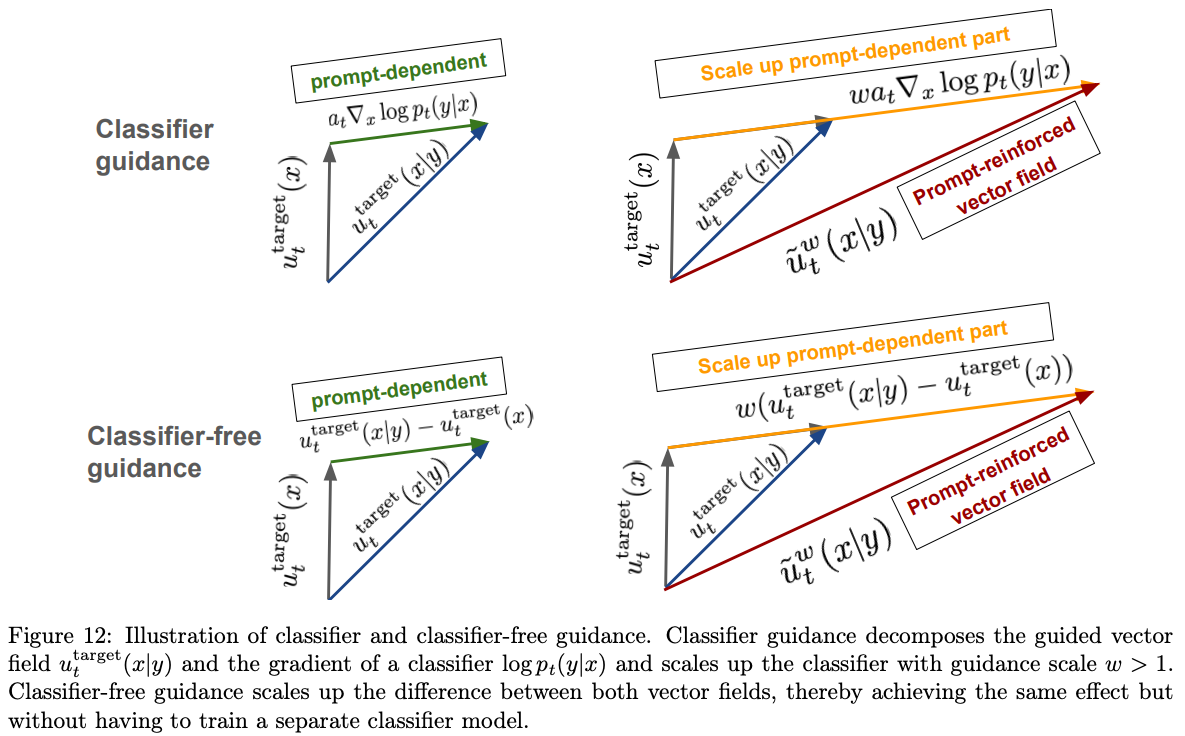
增量形式为:
u~t(x∣y)=uttarget(x∣∅)+w⋅(uttarget(x∣y)−uttarget(x∣∅))
可分解为:
- 基座方向 uttarget(x∣∅):无条件生成方向。
- 增量方向:uttarget(x∣y)−uttarget(x∣∅),表示条件 y 带来的额外语义方向。
- 外推倍增:w>1 时放大条件增量,提高提示词对齐度。
从对比主成分分析角度看,CFG 可理解为:均值平移、放大条件域主成分,并抑制无条件分布中的通用特征。
CFG 的训练
CFG 需要同时得到条件和无条件输出。工程上通过联合训练让同一个网络支持两类输入。
训练策略:
- 引入空标签:扩展一个表示无条件的特殊标志 ∅。
- 条件 Dropout:训练时以概率 η 将真实条件 y 替换为 ∅。
训练目标为:
LCFMCFG(θ)=E■∥utθ(x∣y)−uttarget(x∣z)∥2
其中 E■ 表示如下混合采样:
- 采样真实数据和标签对 (z,y)∼pdata(z,y)。
- 采样时间步 t∼Unif[0,1]。
- 采样对应的中间噪声状态 x∼pt(⋅∣z)。
- 按固定概率丢弃标签,即 y←∅ with prob. η。
训练流程:

推理时,每个时间步分别输入 y 和 ∅ 前向计算,再用 CFG 公式组合输出得到 u~t(x∣y)。
引导尺度的选择
引导尺度 w 控制提示词保真度与样本多样性的权衡。增大 w 近似于从被 pt(c∣x)w 修正后的分布中采样。
- 分布锐化:w>1 会提高高似然区域权重,压低低概率区域。
- 远离决策边界:条件梯度被放大后,采样轨迹更倾向于进入明确的条件簇。
但 w 不能无限增大,过强外推会导致:
- 多样性塌缩:分布收缩到少数模式,不同随机种子生成结果趋同。
- 伪影与过度饱和:线性外推可能使状态超出合理数据范围,产生颜色溢出和结构伪影。
| 引导尺度 w 区间 |
概率空间与景观效应 |
样本多样性 |
提示词保真度 |
视觉特征与实际表现 |
| w≤1.0 |
分布平滑,覆盖范围大 |
高 |
低 |
细节柔和,但主体和条件对齐较弱。 |
| w∈[2.0,7.0] |
分布适度锐化,远离模糊边界 |
中等 |
高 |
主题突出,结构清晰,是常用区间。 |
| w≥10.0 |
分布过度收缩 |
极低 |
极高但僵化 |
容易过饱和、失真并出现伪影。 |
常用动态阈值截断限制预测的无噪信号 x0 范围,以缓解高 w 带来的过饱和和伪影。
推广到扩散模型
高斯路径下,流匹配的边缘向量场与扩散模型的分数函数有仿射线性关系。因此,CFG 的贝叶斯分解可同时用于 ODE 流和 SDE 扩散采样。
将 CFG 引导场放入 SDE 采样:
dXt=u~tθ(Xt∣y)dt+σtdWt
引入 CFG 后,流匹配与传统扩散采样的主要差异:
- 路径平滑度与步数:流匹配路径通常曲率更低,可用较少 ODE 步数生成。
- 确定性与随机性:带 CFG 的流匹配常采用零扩散系数的确定性 ODE 求解,避免随机项破坏优化后的轨迹。
- 视觉差异:同等设定下,流匹配少步采样更倾向于锐利边缘和明确结构;传统扩散更偏平滑纹理与渐变。





