分数函数
Why Score Function?
流匹配通过学习向量场训练流模型;扩散模型通常使用 分数函数 Score Function 描述分布局部结构。
对分类器而言,可用 Softmax 将非归一化分数归一化为概率。一般可写作 p(x)=Zp~(x),其中 p~(x) 是非归一化模型,Z=∫p~(x)dx 是配分函数。
扩散模型需要处理整张图像的高维连续分布,直接计算配分函数 Z 等价于对高维状态空间积分,通常不可行。
分数函数用于绕过配分函数计算。
分数函数的定义
对于任何概率分布 q(x),其分数函数被定义为该分布对数似然函数对空间坐标的梯度,即:
s(x)=∇xlogq(x)
它是 x 处对数似然的梯度。由于配分函数 Z 与 x 无关,∇xlogp(x)=∇xlogp~(x)−∇xlogZ=∇xlogp~(x),因此无需显式计算 Z。
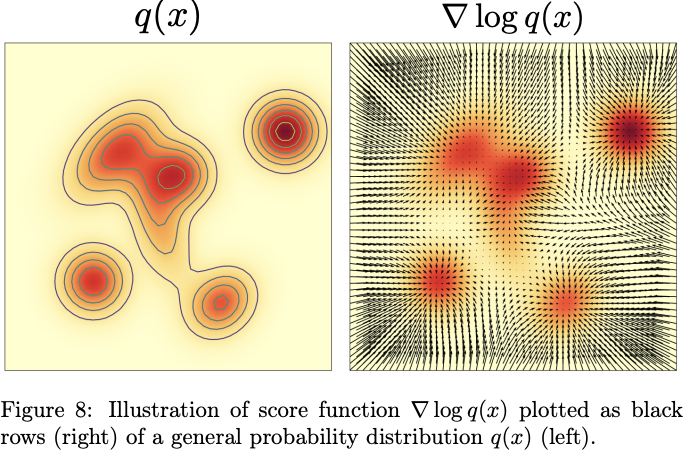
分数函数在数据空间中定义向量场,方向指向概率密度上升最快处。扩散模型学习该向量场,用于指导噪声样本向数据分布演化。
条件分数函数与边缘分数函数
扩散模型和流匹配都使用时间参数 t 控制概率路径。路径从 pinit 演化到 pdata,对应两类分数:条件分数函数和边缘分数函数。
定义与演化
令 δz 表示集中在真实数据点 z∈Rd 的狄拉克分布。条件概率路径 pt(x∣z) 描述单个数据点的加噪/去噪分布,满足 p0(⋅∣z)=pinit 与 p1(⋅∣z)=δz。对应的条件分数函数为 ∇logpt(x∣z)。
边缘概率路径 pt(x) 是条件路径对 pdata(z) 的边缘化结果,即 pt(x)=∫pt(x∣z)pdata(z)dz。边缘分数函数为 ∇logpt(x)。
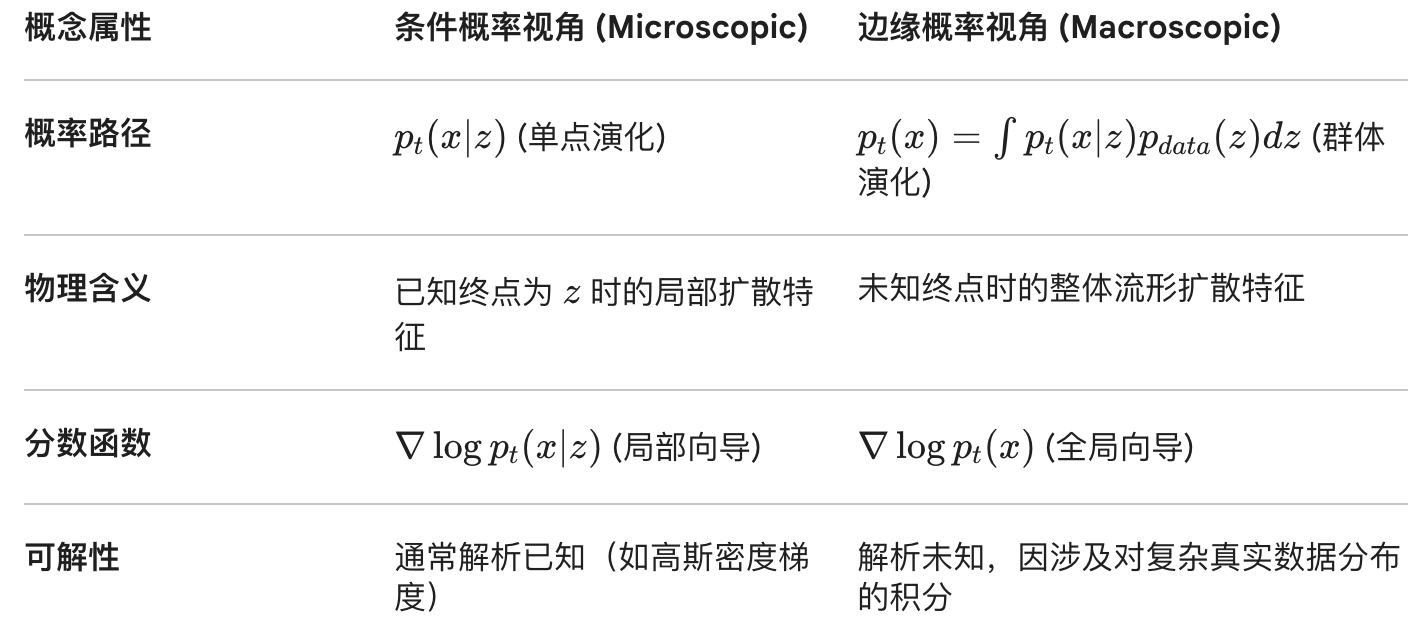
边缘分布函数的导出
目标是用可计算的条件分数表示边缘分数。推导如下:
由对数求导法则:
∇logpt(x)=pt(x)∇pt(x)
代入边缘分布 pt(x)=∫pt(x∣z)pdata(z)dz,并将对 x 的梯度移入积分:
∇logpt(x)=pt(x)∇∫pt(x∣z)pdata(z)dz=pt(x)∫∇pt(x∣z)pdata(z)dz
利用 ∇pt(x∣z)=pt(x∣z)∇logpt(x∣z):
∇logpt(x)=pt(x)∫[pt(x∣z)∇logpt(x∣z)]pdata(z)dz
重排得:
∇logpt(x)=∫∇logpt(x∣z)pt(x)pt(x∣z)pdata(z)dz
权重 pt(x)pt(x∣z)pdata(z) 是后验分布 pt(z∣x)。因此,边缘分数是条件分数在后验分布下的期望。
高斯路径
条件分数函数
设噪声调度函数 αt,βt 满足 α0=0,β0=1 与 α1=1,β1=0。高斯条件路径为:
pt(x∣z)=N(x;αtz,βt2Id)
对多维高斯密度取对数并对 x 求梯度,得到条件分数:
∇logpt(x∣z)=∇x[−2dlog(2πβt2)−2βt21∥x−αtz∥2]=−βt2x−αtz
条件分数关于 x 与 z 线性,方向指向 αtz。方差 βt2 越大,分数幅度越小;方差趋近于 0 时,分数幅度增大。
向量场与分数函数的数学等价性:高斯路径下,流匹配的目标向量场与扩散模型的分数函数存在线性转换。条件向量场为:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
定义时间系数:
at=βt2αtα˙t−β˙tβt
bt=αtα˙t
代入条件分数后:
uttarget(x∣z)=(βt2αtα˙t−β˙tβt)(βt2αtz−x)+αtα˙tx
uttarget(x∣z)=at∇logpt(x∣z)+btx
由于 at,bt 只依赖时间,边缘化后有:
uttarget(x)=at∇logpt(x)+btx
因此,在高斯路径下,学习边缘目标向量场与学习边缘分数函数等价。
Denoiser 重参数化
由上述线性关系可得到 去噪器 Denoiser 视角。定义边缘去噪器为后验均值:
Dt(x)=∫zpt(x)pt(x∣z)pdata(z)dz=Ez∣x[z]
预测 Dt(x) 后即可恢复无条件向量场和分数函数。工程上常预测原始图像或噪声残差,而不是直接预测分数,因为纯噪声阶段的分数模长可能很大,数值稳定性较差。
基于 SDE 的概率采样
扩散模型使用 SDE 采样,在确定性向量场外加入随机噪声,并通过分数项控制分布演化。
SDE Extension Trick
SDE Extension Trick:在确定性 ODE 轨迹中加入随机扰动,同时保持任意时刻的边缘分布仍为 pt(x)。
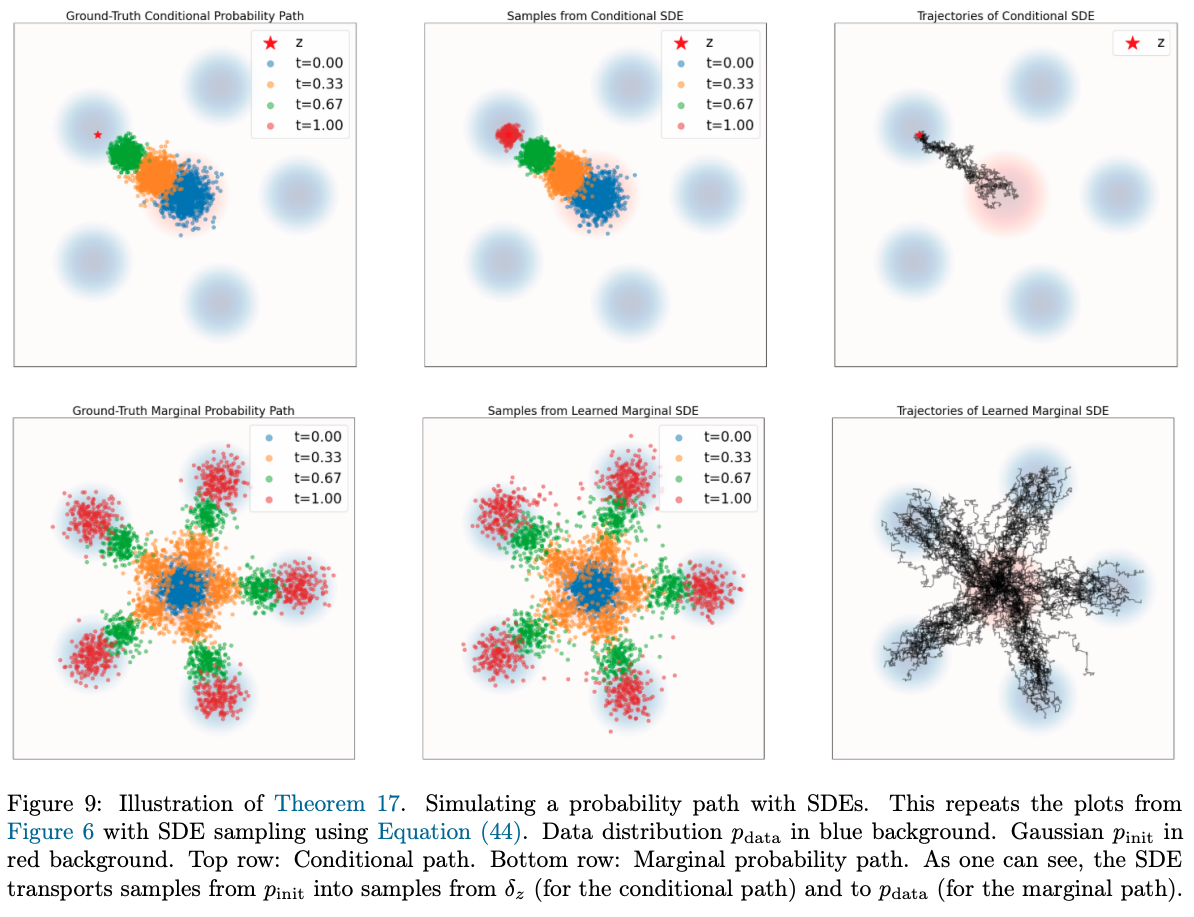
对任意时间依赖扩散系数 σt≥0,构造 SDE:
dXt=[uttarget(Xt)+2σt2∇logpt(Xt)]dt+σtdWt
初始条件为 X0∼pinit。其中 σtdWt 注入布朗噪声,会扩散分布;2σt2∇logpt(Xt) 则沿密度上升方向补偿该扩散,使宏观边缘分布仍沿目标路径演化。
Fokker-Planck 方程
可用 Fokker-Planck 方程证明上述 SDE 的边缘分布确实为 pt(x)。FPE 描述 Ito SDE 所诱导的概率密度随时间演化。
对一般 Ito SDE:dXt=μt(Xt)dt+σtdWt,对应 FPE 为:
∂tpt(x)=−∇⋅(pt(x)μt(x))+2σt2Δpt(x)
它包含两项:
- 对流/漂移分量 Drift Term [−∇⋅(ptμt)]:对应确定性向量场对概率质量的搬运。
- 扩散分量 Diffusion Term [2σt2Δpt(x)]:对应布朗噪声引起的密度扩散,形式类似热方程。
将 SDE Extension Trick 中的漂移项代入 FPE:
μt(x)=uttarget(x)+2σt2∇logpt(x)
计算对流项:
−∇⋅(pt(uttarget+2σt2∇logpt))
展开散度:
=−∇⋅(ptuttarget)−2σt2∇⋅(pt∇logpt)
由 ∇logpt=pt∇pt,有 pt∇logpt=∇pt,因此第二项为:
−2σt2∇⋅(∇pt)=−2σt2Δpt
漂移项贡献为:
−∇⋅(ptuttarget)−2σt2Δpt
代回 FPE:
∂tpt=(−∇⋅(ptuttarget)−2σt2Δpt)+2σt2Δpt
扩散项与分数补偿项抵消,剩下:
∂tpt=−∇⋅(ptuttarget)
这就是纯 ODE 流模型的连续性方程。因此,该 SDE 与目标 ODE 具有相同的边缘分布演化;随机性只改变样本路径,不改变宏观概率路径。
Langevin Dynamics
若目标分布不随时间变化,即 pt=p 且 ∂tpt=0,则目标向量场可取 uttarget=0。
代入 SDE Extension Trick:
dXt=2σt2∇logp(Xt)dt+σtdWt
该式为 过阻尼朗之万方程 Overdamped Langevin Equation。在 MCMC 和分子动力学中,它用于采样复杂平稳分布。若满足遍历性条件,过程最终收敛到目标分布 p。早期基于分数的生成模型也利用朗之万步骤进行降噪采样。

分数匹配
ODE/SDE 采样都需要边缘分数 ∇logpt(x),但该量依赖未知的 pdata。因此需要训练分数网络 stθ:Rd×→Rd 来近似它。
显式分数匹配
最直接的方法是最小化预测分数与真实边缘分数的距离,称为 显式分数匹配 Explicit Score Matching:
LSM(θ)=Et∼Unif,x∼pt[∥stθ(x)−∇logpt(x)∥2]
该损失的问题是:一方面需要未知的 ∇logpt(x);另一方面,即便通过积分分部消去显式依赖,低密度区域的分数估计仍不稳定。
去噪分数匹配
去噪分数匹配 Denoising Score Matching 将目标从未知边缘分数转为已知条件分数。
定义条件去噪分数匹配损失:
LCSM(θ)=Et∼Unif,z∼pdata,x∼pt(⋅∣z)[∥stθ(x)−∇logpt(x∣z)∥2]
这里先采样真实数据 z 和时间 t,再由已知条件路径采样 x。目标 ∇logpt(x∣z) 可计算,高斯路径下有闭式解。
核心结论:
边缘分数匹配损失等同于去噪分数匹配损失加上一个常数项,即 LSM(θ)=LCSM(θ)+C。
两者对 θ 的梯度相同,因此最小化 LCSM 等价于优化不可直接计算的 LSM。关键在于处理 LSM 展开后的交叉项。
利用贝叶斯重排公式 ∇logpt(x)=∫∇logpt(x∣z)pt(x)pt(x∣z)pdata(z)dz:
∫01∫xpt(x)⋅stθ(x)T⋅[∫z∇logpt(x∣z)pt(x)pt(x∣z)pdata(z)dz]dxdt
外层 pt(x) 与后验表达式分母抵消,得到:
∫01∫x∫zstθ(x)T∇logpt(x∣z)pt(x∣z)pdata(z)dzdxdt
这正是联合分布下的期望:Et∼Unif,z∼pdata,x∼pt(⋅∣z)
展开平方项后,剩余差异只是不依赖 θ 的常数 C。因此,用条件分数训练即可得到边缘分数的最优估计。
DDPM
DDPM 是去噪分数匹配的工程化形式。考虑高斯条件路径 pt(x∣z)=N(x;αtz,βt2Id)。
条件分数为 −βt2x−αtz。含噪样本通过重参数化得到:x=αtz+βtϵ,其中 ϵ∼N(0,Id)。
代入条件分数:
∇logpt(x∣z)=−βt2(αtz+βtϵ)−αtz=−βt2βtϵ=−βtϵ
代入 DSM 损失:
LCSM(θ)=Et,z,ϵ[stθ(x)+βtϵ2]=Et,z,ϵ[βt21βtstθ(x)+ϵ2]
直接预测 stθ(x) 会在 βt→0 时产生数值不稳定。Ho et al. (2020) 将网络改为预测噪声 ϵtθ(x)。
令 ϵtθ(x)=−βtstθ(x),并去掉全局权重 βt21,得到 DDPM 降噪损失:
LDDPM(θ)=Et∼Unif,z∼pdata,ϵ∼N(0,Id)[ϵtθ(αtz+βtϵ)−ϵ2]
算法流程:

DDPM 通过预测噪声间接学习分数函数,使训练目标稳定且易实现。





