流模型和扩散模型需要用神经网络参数化向量场 utθ(x∣y)。该函数包含三个输入和一个输出:
- 输入:空间向量 x∈Rd(图像像素或潜变量);引导变量 y∈Y(如文本、类别等);时间步长 t∈[0,1]。
- 输出:预测的向量场 utθ(x∣y)∈Rd。
低维任务可直接拼接 (x,y,t) 并使用 MLP。图像和视频生成维度高,需要能同时处理带噪视觉状态、提示词和时间信息的结构。
嵌入条件变量
时间嵌入
简单模型可直接输入时间步 t;实际生成模型通常用傅立叶特征将 t 嵌入高维空间,以表达不同噪声水平下的时间依赖:
TimeEmb(t)=d2[cos(2πw1t)…cos(2πwd/2t),sin(2πw1t)…sin(2πwd/2t)]T
其中频率系数 ωi 表示为:
wi=wmin(wminwmax)d/2−1i−1,i=1,…,d/2
该形式不是唯一选择,但能将时间映射到 d 维隐空间,并保持 ∣∣TimeEmb(t)∣∣=1(sin2+cos2=1)。
类嵌入
若 yraw∈{0,…,N} 是类别标签,可为每个类别学习一个嵌入向量 y,并与向量场参数一起训练。
文本提示词嵌入
若 yraw 是文本提示词,通常用冻结的预训练文本模型将文本嵌入连续向量空间。常见选择:
- CLIP:生成全局语义嵌入 y=CLIP(yraw)∈RdCLIP。
- T5:提供细粒度的序列嵌入,形如 PromptEmbed(yraw)∈RS×k,允许模型通过注意力机制关注特定单词。
DiT 结构
图像可表示为张量 x∈RCimage×H×W。DiT 使用注意力机制参数化向量场,设隐藏维度为 d,层数为 L,注意力头数为 h。
与 Vision Transformer 类似,DiT 将图像切成 Patch,映射为 token 序列,经 Transformer 处理后再 Depatchify 回原图尺寸。
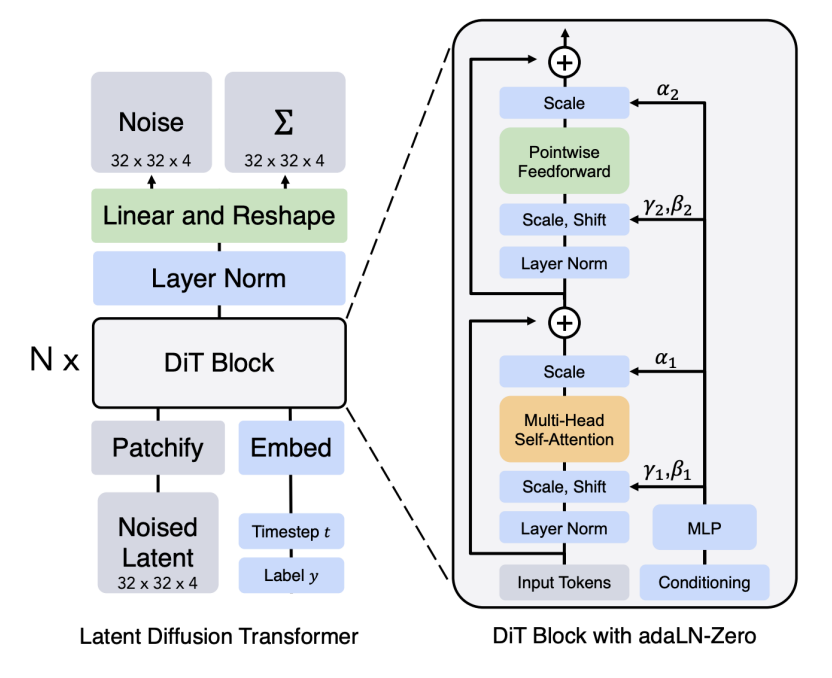
结构流程:
- Patch 化:输入一张图片张量 x∈RC×H×W,以 P×P 的 Patch 大小,产生 N=(H/P)⋅(W/P) 个 Patch;每个 Patch 做 Patchify 之后的的维度 C′=CP2。表示为 Patchify(x)∈RN×C′。
- Patch 嵌入:学习一个矩阵 W∈RC′×d 来将每个 Patch Token 潜入到隐藏空间 d 中。表示为 x~0=PatchEmb(x)=Patchify(x)W∈RN×d。
- 时间/提示词嵌入:t~=TimeEmb(t)∈Rd 和 y~=PromptEmbed(y)∈RS×d
- 输入 DiT:每层接收 x~i,t~,y~,并计算 x~i+1=DiTBlock(x~i,t~,y~)∈RN×d,(i=0,…,L−1)。Block 主要包含 Patch 自注意力、提示词交叉注意力和时间控制的 AdaLN。
- 解 Patch:学习一个矩阵 W~∈Rd×C′ 来将 DiT 的输出映射回到一张图片,即:u=Depatchify(x~NW~)∈RC×H×W。这个 u 就是模型的输出,也就是我们需要预测的向量场 utθ(x∣y)。
DiT Block
DiT Block 的核心组件:
-
缩放点积注意力:
Attn(Q,K,V)=softmax(dhQKT)V∈RN×dh
-
多头注意力:学习投影矩阵 WQ(h),WK(h),WV(h)∈Rd×dh。定义 headh(x,z)=Attn(xWQ(h),zWK(h),zWV(h)),其中 z=x 为自注意力,z=y 为交叉注意力。最后拼接并投影:
MultiHeadAttention(x,z)=Concat(head1,…,headh)WO∈RN×d
-
AdaLN 自适应层归一化:用 MLP g:Rd→R2d 从时间嵌入 t~ 预测 (γ,β)=g(t~)。初始化时令 g 输出零,使 Block 初始接近恒等映射,提高训练稳定性。
AdaNormt~(x)=(1+γ)⊙Norm(x)+β
计算流程:
- 自注意力:x←x+gself(t~)⋅MultiHeadAttention(AdaNormt~(x),AdaNormt~(x))
- 交叉注意力:x←x+gcross(t~)⋅MultiHeadAttention(AdaNormt~(x),y~)
- 前馈网络:x←x+gMLP(t~)⋅MLP(AdaNormt~(x)) (注:g…(t~) 为学习到的门控参数)。
U-Net
U-Net 是扩散模型中的另一类主流架构,本质是卷积神经网络,特点是输入与输出形状一致。
在扩散模型中,我们需要构建一个参数化的向量场:
x↦utθ(x∣y)
在固定 y,t 时,输入 x 和输出 u 都是图像形状,因此 U-Net 适合参数化该向量场。
U-Net 结构
典型 U-Net 包含:
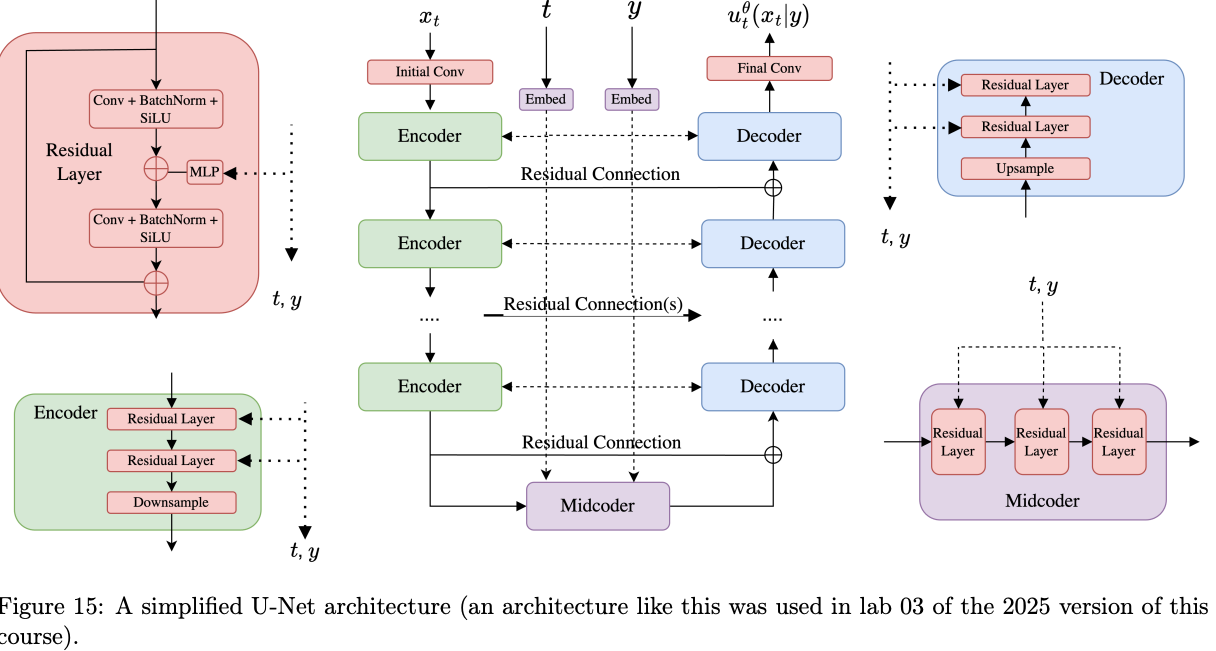
- 编码器序列 Encoders:记为 Ei。负责特征提取和空间压缩。
- 解码器序列 Decoders:记为 Di。负责特征融合和空间还原。
- 中层处理块 Midcoder:记为 M,指编码器和解码器之间的瓶颈层。
计算流程
以 256×256 RGB 图像为例,输入维度为 (3,256,256):
-
输入阶段:xtinput∈R3×256×256,表示带噪图像或潜变量。
-
编码压缩阶段:xtlatent=E(xtinput)∈R512×32×32,分辨率降低、通道数增加。
-
中间处理阶段:xtlatent=M(xtlatent)∈R512×32×32,维度保持不变。
-
解码还原阶段:xtoutput=D(xtlatent)∈R3×256×256,上采样恢复空间分辨率和通道数。
设计细节
- 层组成:编码器和解码器通常由一系列卷积层组成,中间夹杂着激活函数(如 ReLU)、池化操作(Pooling)等。
- 预编码块:输入通常先经过初始块,在不改变分辨率的情况下增加通道数。
- 残差连接:编码器和解码器之间直接连接,补充压缩过程中丢失的空间位置信息,改善纹理和边缘细节。





