
ADS-01:跳表
背景
跳转表(Skip List)作为一种基于概率平衡的链表数据结构,自 William Pugh 教授于1989年首次提出并在1990年发表经典论文《Skip Lists: A Probabilistic Alternative to Balanced Trees》以来,便因其实现逻辑的极简性与运行效率的卓越性,在众多核心系统架构中占据了不可替代的关键地位。
在深入探讨跳转表的底层算法与数学机制之前,有必要首先回答一个在工程实践中被反复提及的经典问题:作为目前全球应用最广泛的内存数据库,Redis 在设计其核心的有序集合时,为何毅然放弃了传统的平衡二叉搜索树(如红黑树或 AVL 树),转而选择了跳转表结合哈希表的混合架构?根据 Redis 创始人 Antirez 的架构设计哲学以及海量开源工程实践的反馈,这一决策绝非偶然,而是基于内存灵活性、硬件缓存友好性以及系统可维护性三个维度的深度考量。
首先,跳转表在内存占用的表现上展现出了极强的参数化灵活性。在传统的平衡二叉树体系中,每一个节点都必须严格维护至少两个固定的指针(左子节点与右子节点),同时还需要存储用于维持树平衡的额外元数据(例如红黑树的颜色位或 AVL 树的高度差因子)。而在跳转表中,每个节点所携带的指针数量完全取决于一个概率参数控制的随机函数。系统架构师可以通过动态调整节点具有特定层数的概率参数,精细化地控制整体架构的内存开销,使其在大多数常规配置下,比传统的 B 树或红黑树更加节省内存空间。
其次,现代计算机硬件的性能极大地依赖于 CPU Cache Locality,而跳转表在应对大范围的区间数据遍历时表现出了极佳的硬件亲和力。在 Redis 的业务场景中,有序集合经常需要执行范围查询操作(例如获取积分排名前一百名的用户)。若采用平衡树架构,区间遍历操作本质上等同于树的中序遍历,这要求程序计数器在父节点与子节点之间进行频繁的非连续内存跳转。相反,跳转表的最底层(Level 0)实际上就是一条将所有数据按顺序串联起来的单向或双向链表。一旦通过高层索引锁定了范围查询的起点,后续的遍历操作完全等价于最基础的链表线性遍历,这种线性访问模式极大地提升了 CPU 预取指令的命中率,其缓存局部性表现不仅不弱于平衡树,在某些连续内存分配的场景下甚至更胜一筹。
最后,工程实现的简洁性与系统扩展的灵活性是决定技术选型的重要软性指标。平衡树在执行插入与删除操作时,为了修复被破坏的平衡条件,必须执行复杂的左旋、右旋以及颜色翻转逻辑。这种复杂性不仅陡增了代码的开发与调试难度,也使得后续的定制化改造步履维艰。跳转表的算法逻辑纯粹依赖于简单的指针修改与随机数生成,没有任何全局的平衡约束负担。正是得益于这种大道至简的架构设计,Redis 开源社区的一位贡献者能够以极少的代码侵入量,通过在跳表的指针结构中简单增设一个跨度属性,便完美实现了一个时间复杂度仅为对数级别的排名查询功能。这种灵活的扩展能力是红黑树等刚性数据结构所难以比拟的。
数学基础
二项分布的统计特性
二项分布(Binomial Distribution)是离散概率分布体系中最基础的模型之一。假设我们进行一系列相互独立的随机试验,每次试验只有“成功”和“失败”两种可能的结果,且每次试验成功的概率固定不变。在数学定义上,设 为非负整数,代表总试验次数; 为单次试验成功的概率。术语 表示一个随机变量,其物理意义为在这一系列 次独立试验中所观察到的总成功次数。
二项分布 的数学期望(即平均预期成功次数)为总次数与成功概率的乘积 ,而其方差则为 。在跳转表的后续理论分析中,当我们试图评估在某个极其稀疏的高层级链表中,预期会存在多少个节点时,二项分布模型将发挥关键的指导作用。
负二项分布的反向逻辑
与二项分布探讨“固定试验次数下的成功次数”这一正向逻辑不同,负二项分布(Negative Binomial Distribution)探讨的是一种反向的等待时间逻辑。在数学定义上,设 为非负整数,代表我们所期望达到的目标成功次数; 依然为单次独立试验成功的概率。术语 表示一个随机变量,其物理意义为:在恰好获得第 次成功之前,我们必须经历并观察到的“失败”的总次数。
在跳转表的语境中,负二项分布的重要性无可替代。当我们对跳转表的搜索路径进行复杂的数学建模时,William Pugh 采用了一种逆向思维:不是从起点向终点分析,而是从目标节点开始,反向向左上方爬升回跳表的头节点。在这个反向爬升的过程中,“向左移动回退”被定义为一次失败的试验,而“向上一层爬升”则被定义为一次成功的试验。如果我们想知道在成功向上爬升 层之前,预期会遭遇多少次向左的回退,这就精准契合了负二项分布的模型。根据理论推导,负二项分布 的数学期望为 ,其方差为 。这一公式构成了跳转表搜索时间复杂度证明的核心基石。
几何分布与节点层数的生成
几何分布(Geometric Distribution)可以被视为负二项分布在一种极其特殊情况下的退化形式,即当我们仅仅渴望获得第一次成功()时所经历的过程。几何分布的经典定义描述了在 次伯努利试验中,一直进行到第 次才首次见证成功的概率。换言之,前 次试验全部以失败告终,唯独第 次取得了成功。其概率质量函数可以清晰地表达为:,其中 可以取任何正整数。
如果我们将随机变量定义为获得第一次成功所需的总试验次数(包含那一次成功),那么其数学期望 等于 ;如果将其严格定义为首次成功前遭遇的失败次数,则期望为 。在跳转表的底层算法实现中,每一个新插入节点的层数高度完全是由一个随机函数决定的。这个随机函数会不断地“抛硬币”,只要结果是继续提升(概率为 ),层数就加一,直到第一次出现停止提升的结果(即发生“失败”)为止。因此,跳转表中任意一个节点最终能够生长到某一层数的概率,完美契合几何分布的数学特征。
伯努利不等式的运用
在评估有限元素组成的跳转表中,所有节点中可能出现的理论最大层数上界时,需要利用到一个关键的概率放缩技巧——伯努利不等式:设 与 均为正整数,有 。
回到跳转表的问题。考虑到 作为一个代表层数的变量,必然是一个大于等于1的正整数。当 时,,因此 的取值范围被严格框定在 的区间内。这一取值范围完美满足了伯努利不等式 的严苛前提条件。将 的具体代数式代入已证的定理中,我们即可毫无悬念地得出结论:,整理后即为 。这一看似不起眼的数学放缩技巧,将在后续论证跳转表最大活跃层数概率上界时,发挥一锤定音的关键作用。
跳转表:数据结构设计与核心算法剖析
为了在有序数据集中实现快速的查找操作,开发人员通常面临两种基础结构的抉择。一方面,有序数组支持利用二分查找算法实现 的极速定位,但其致命缺陷在于插入与删除操作由于需要进行大规模的内存数据搬移,导致时间复杂度退化为 。另一方面,标准单链表虽然允许在已知内存位置进行 的原位插入与删除,但由于缺乏随机访问能力,其查找任何一个节点都必须从头进行线性遍历,耗时同样高达 。为了融合这两种结构的优势,平衡二叉树应运而生。然而,正如 William Pugh 在其开创性论文中所指出的,平衡树在处理完全随机顺序的数据插入时表现得尚且令人满意,但一旦遭遇近似有序或完全有序的数据序列,为了抵御结构退化为单链表的风险,算法必须强制介入并执行大量繁琐且极易出错的树旋转重构操作以维持严苛的平衡约束。
跳转表(Skip List)正是在这样一种寻求“高性能与低复杂度并存”的诉求下诞生的概率性替代方案。
节点数据结构与宏观配置参数
在理解了跳转表的宏观运作哲学之后,我们需要深入到代码实现的微观层面。一个标准跳转表的 C++ 核心数据结构定义包含了全局配置常量与节点实体两个部分。
首先,系统必须在全局作用域内定义两个至关重要的配置参数:
1 | const int MAX_LEVEL = 16; // 约束跳表向上生长的绝对物理最大层数 |
对于这两个参数的设定依据,绝非随意的魔法数字(Magic Numbers)。概率因子 P 决定了相邻两层之间节点的稀疏程度,通常设定为 或 。而 MAX_LEVEL 则是为了防止在极端巧合下,某个节点的层数无限制增长导致内存溢出而设定的硬性天花板。Pugh 在论文中给出了明确的指导原则:对于一个预期最大容量为 的系统,安全且最优的物理层数上限应当被设定为 。如果我们在系统中采用 的概率配置,并设置 MAX_LEVEL = 16,那么这个跳转表在数学理论上足以高效支撑高达 个元素的并发存储与检索,而不会出现明显的性能衰减。
接下来是跳转表节点实体(Node)的内存结构定义。与传统双向链表仅维护前驱和后继指针,或二叉树仅维护左右子树指针截然不同,跳转表节点的最大特色在于其拥有一组动态长度的前进指针集合。
1 | // 核心跳表节点实体结构 |
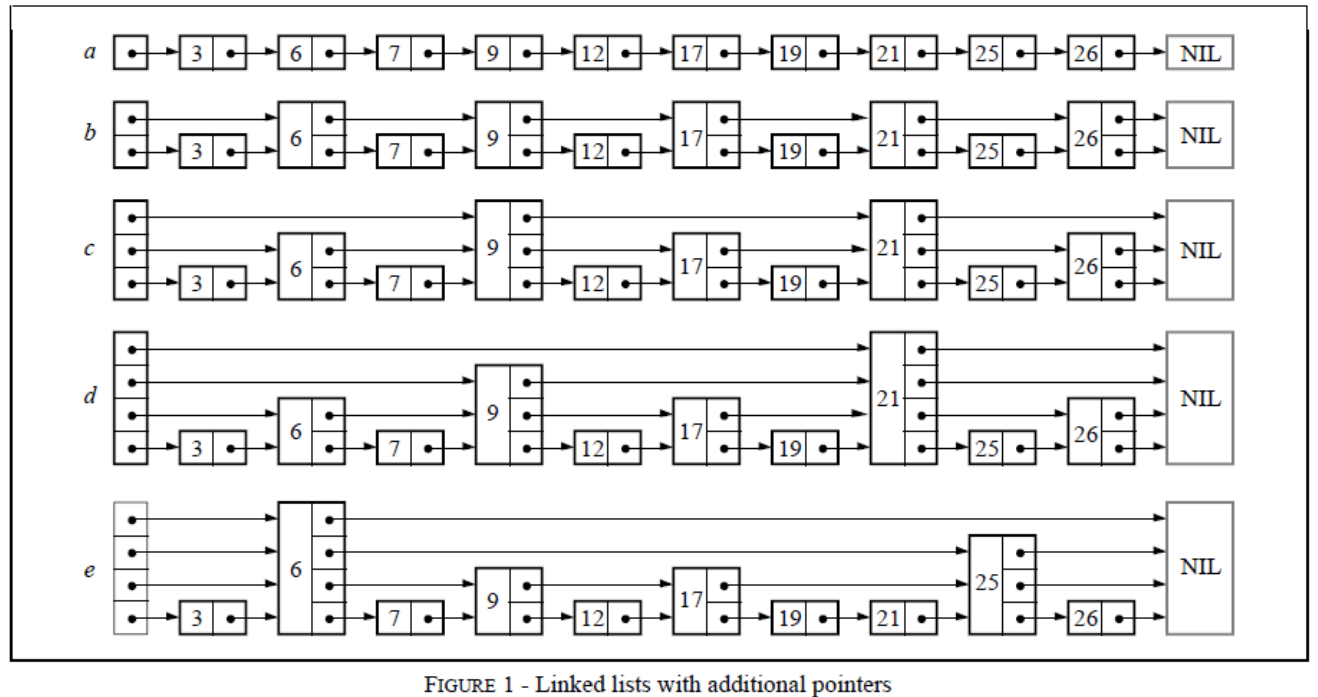
在上述代码中,vector<Node*> forward 扮演了立体交通网中“车道”的角色。数组中的每一个元素 forward[i] 都明确指向了当前节点在第 层级的直系后继节点的内存内存地址。如果当前节点在某一层是链表的尾部,则该指针将指向 nullptr(或者在某些哨兵节点的实现中指向一个特殊的 NIL 节点,其键值被设定为正无穷大)。
理想启动层数公式
在评估跳转表性能时,一个关键的优化问题浮出水面:既然跳转表拥有多层结构,那么算法在执行搜索时,究竟应该从哪一层作为起点开始遍历最为合理?Pugh 有一个重要论断:“深入的数学分析向我们昭示,理想的搜索起点应当设定在这样一个特定的层数 :在这一层中,我们预期恰好能够遭遇 个节点。” 并且给出了结论公式 。
我们的推导始于对每一层节点密度的期望值计算。假设当前跳转表系统中总共容纳了 个独立节点。由于每一个节点的层高生成过程都遵循概率为 的几何分布(每次晋升的成功率均为 ),如果我们将最底层的一般链表定义为第1层(在数组索引中对应0),那么任意一个随机节点能够成功晋升并存活在第 层的概率精确地等于 。
依据概率论中期望值的基本线性法则,将系统内节点总数乘以单节点存在于该层的概率,即可得出在第 层的预期节点总数规模,我们将其记作函数 :
此时,我们引入 Pugh 的理想假设条件。我们迫切希望找到一个层数标识符 ,使得如果系统刚好生长到这一层,该层内存在的节点数量期望值恰好等于 。我们将这一目标条件转化为代数方程式:
接下来进行代数恒等变形。利用指数法则将等式左侧拆解:
由于概率 是一个介于0和1之间的合法实数, 不可能为零,因此我们可以在等式两边同时消去 ,得到一个极其简洁的中间形态:
将含有未知函数 的项保留在等式一侧,把常数 移至对立面:
为了从指数位置解出目标函数 ,我们在等号两侧同时取以自然对数或任意基数为底的对数运算(此处采用以 为底数或利用换底公式)。取对数后,等式转变为:
最后一步,将等式两边同时除以 ,并将负号吸收到对数函数的内部:
根据对数体系的基础换底公式,上式可以完美地浓缩为:
这一推导不仅从数学的严谨性上证实了 PPT 中的直接结论,更为后续我们在进行时间复杂度反向爬升分析,以及在工业级代码中设定安全的内存上限提供了无可辩驳的理论基石。
动态随机层数生成策略(randomLevel 函数)
平衡二叉树之所以在实现上令人感到棘手,根本原因在于其在插入或删除节点后,需要根据树的全局拓扑结构来决定如何进行局部旋转调整。而跳转表彻底抛弃了这种基于全局状态的依赖。一个新节点在插入系统时,它最终能够获得多高的“楼层待遇”,完全取决于一个独立且毫无记忆的随机掷骰子过程。
这种机制在 C++ 代码中通过 randomLevel 函数得以具象化实现:
1 | int randomLevel() { |
这种看似随意的算法设计,实则蕴含着精妙的自适应平衡智慧。由于每一个节点的层高是在其插入瞬间通过本地随机数独立决定的,它完全屏蔽了外部输入数据流的顺序性干扰。无论开发者是向跳转表中输入完全随机的乱序数字,还是输入从1到100万的严格递增序列,跳转表的宏观多层结构分布始终稳如泰山,它永远不会像朴素的二叉搜索树那样,在面对有序输入时灾难性地退化成一条毫无搜索效率的单链表( 复杂度的最差情境)。这种免疫极恶劣输入样本的能力,是跳转表被现代数据库广泛接纳的核心要素之一。
搜索算法实现细节解析(Search)
跳转表的搜索操作完美地践行了“从高处俯瞰,逐步逼近”的哲学。其目标是查明系统内是否存在包含特定键值的节点。
1 | // 搜索算法:接收一个目标整数 target,返回一个布尔值代表其是否存在 |
插入算法体系与前驱轨迹记忆(Insert)
相较于单纯的只读搜索操作,将一个全新节点植入跳转表体系不仅要求精准找到其物理落脚点,还必须确保这个新节点能够与各层原有的链路网络无缝对接,不能造成任何链表断裂。在此处,算法引入了一个被称作 update 数组的核心辅助工具。
可以把 update 数组想象成一本“航海日志”。当你在多层网络中不断向右推进、并且在遇到障碍不得不向下“降级”的时候,这本日志会忠实地记录下你在每一层最终停留的最后一个节点的内存地址。换句话说,update[i] 保存了在第 层中,新节点未来插入位置左侧紧邻的那个“前驱节点”。有了这本日志,当新节点随机生成了自己的楼层高度后,系统就可以按图索骥,直接找到每一层需要被剪断并重新拼接的链表接头。
1 | void insert(int value) { |
删除算法体系与幽灵层级清理(Delete)
删除算法在宏观流程上是插入算法的镜像逆操作。它同样高度依赖于 update 数组来锁定目标节点的左侧防御防线(前驱节点)。在成功确认目标身份后,算法会指令各层的前驱节点无情地将指针跨越目标节点,彻底将其从数据结构的社会关系网中抹除。
1 | bool erase(int value) { |
算法时间复杂度与概率空间的深度解析
本节将步入 反向爬升分析法(Backwards Climb Analysis)。在这一体系下,我们将通过严密的代数运算与概率放缩,无可辩驳地证明跳转表在时间成本上的 理论天花板。
逆反直觉的视角转移:反向搜寻路径
在评估常规数据结构的搜索成本时,我们的本能驱使我们顺着代码的执行轨迹,从跳表的起始头节点出发,自上而下、从左向右地统计比较的次数。然而,由于前向探索的视野中布满了未知的随机节点,导致正向分析的概率状态空间呈现出一种极度发散的混沌状态。为了破局,Pugh 祭出了逆向工程的思维模式:**假设我们已经站在了成功锁定的目标节点上,现在我们要反转时空,通过一条最短路径反向退回到跳表的左上角原点。
为了让这种反向追踪在逻辑上自洽,我们引入一个思想实验的法则:尽管在现实物理内存中,所有节点的层数高度在它们插入的那一瞬间就已经固化了;但在我们的反向分析视角里,我们假装这些节点的真实高度是被一层迷雾笼罩的。只有当我们反向攀爬、脚步真切地踏上某一层指针的时候,迷雾才会散去,该节点是否拥有更高一层的结构才会由一个临时掷出的硬币(概率为 )来决定。这种“延迟决定论”将原本复杂的静态结构坍缩为了一个极其简洁的马尔可夫动态过程。
在这个充满未知的反向爬升旅途中,如果我们截取任意一个瞬间,假设我们此刻正悬停在某个未知节点 的第 层的左侧边缘。我们的雷达对 节点左侧的世界一无所知,对 节点本身的最终高度也一无所知,我们唯一能够确认的客观事实是:既然我们能够踏足这里,说明 节点的层高至少达到了 级(此即为Situation a)。
立足于这个至少为 级的基准点,我们有两条岔路口:
-
岔路口一(向左撤退):对应 Situation b。 当我们试图在当前节点继续向更高的 层攀登时,系统残酷地宣告 节点的真实高度刚好就停留在 层,无法继续向上。既然此路不通,我们唯一的出路就是沿着第 层的连接索,平移向左撤退到上一个前驱节点。 那么,这种情况发生的概率是多少呢?基于我们已经知道 高度至少为 的条件前提下,它的高度不再继续向上突破 的条件概率,等同于在进行高度生成随机测验时,丢出了不符合提升条件的数字的概率。毫无疑问,这个概率是 。
-
岔路口二(乘风直上):对应 Situation c。 系统给我们带来了好消息:浓雾散去, 节点的真实高度突破了 的限制,至少达到了 或更高。这简直是天赐良机!这意味着我们完全不需要进行任何耗时的向左撤退,可以直接在当前原地的电梯井中,垂直向上攀升一个层级,抵达第 层。 同理,在高度至少为 的已知条件下,高度继续突破延伸到 的条件概率,精确地等价于随机函数判定提升成功的概率,即 。
期望代价方程 的代数演绎
在明确了基本的状态转移规律后,我们引入一个核心的数学分析函数:定义 为在一条拥有无穷无尽元素的假想跳转表中,为了实现在垂直空间内总共向上爬升 个独立层级,我们预期所需耗费的总体移动步数(包含所有的向左和向上动作)。
-
逻辑起点:如果根本不需要爬升任何高度(),预期代价自然是零,因此得到边界条件:。
-
状态组装:如果我们需要爬升 层,我们在踏出第一步时将面临前文所述的概率分岔。由此构建出预期代价的递归状态转移方程:
对两种情境下的后续代价进行精细拆解:
-
解析 Situation b(向左撤退):虽然我们耗费了 1 次宝贵的移动步数向左平移,但令人沮丧的是,我们在垂直方向上毫无建树。我们距离爬升 层的目标依然剩下完整的 层需要跨越。由于面对的是无穷列表,向左移动后的节点依然是一个充满了相同未知概率的盲盒。因此,这种情况下未来的整体预期代价等于我们刚刚用掉的 1 步,加上再次面对爬升 层挑战的预期成本 。数学表达为:。
-
解析 Situation c(垂直跃迁):我们同样耗费了 1 步动作,但这 1 步让我们成功地在垂直方向上斩获了 1 个层级。此时,我们距离爬升 层的宏伟目标,仅仅只剩下 层需要征服。因此,这种情况下的未来整体预期代价等于:。
将这些精细拆解的微观表达式代入宏观的概率方程式中,我们得到:
这就是揭示跳转表性能密码的核心等式。接下来,我们将如同剥洋葱一般,对这个等式进行纯粹的代数化简。
首先,将右侧的括号利用分配律彻底拆解铺平:
提取共有项并简化常数:
注意到式子中包含一个 和一个 以及一个 ,它们互为抵消:
为了解出 ,我们将等号右侧孤立的 通过减法移至左侧,发现两边同时消去了 ,等式骤然变得清爽:
将带有负号的 整体迁移至等号左端:
在等式两端同时除以概率常量 :
仔细端详这个最终形态的等式,这在离散数学中是一个最为标准的一阶线性常系数差分方程(等差数列递推公式)。它清晰地告诉我们:每当你多设定一层爬升目标,你的预期步数账户上就会固定增加一个常数代价 。由于我们的基准点是 ,经过连续 次展开迭代后,结论很明显:
即在一个无边无际的理想跳转表中,你想要向上攀登 层楼高,预期总共只需要付出 次的脚步跨越。
有限元素集合的总搜索成本界定
上述基于 的完美推导是建立在列表具有无穷宽度的理想化(同时也是一种极度悲观的)假设之上的。在现实世界的计算机内存中,跳转表容纳的元素总量 是确信且有限的。在处理真实的 个元素的有界结构时,我们的反向探测必须被精准地切分为两个截然不同的阶段来独立计算。
第一阶段:从地表 Level 1 爬升至理想高度
在起始阶段,我们完全可以照搬 的结论。从最底层的 Level 1 开始向上反向攀爬,一直攀爬到前文推导出的理想启动层级 ,我们总共需要跨越 个高度阶梯。根据无穷列表的保守公式,这一阶段所需的预期移动步数的绝对上限为:
为何说这仅仅是一个保守的上限?因为在有限长度的跳表中,我们在向左反向试探的过程中,极大概率会提前撞上一面无法逾越的空气墙——跳表的虚拟头节点(Header)。一旦我们的背部抵住头节点,向左退却的路就被彻底封死了。此时我们别无选择,只能沿着头节点的电梯井垂直向上移动,在这个过程中将不再产生任何耗时的水平向左动作。因此,实际发生的步数一定 只少不多。
第二阶段:在 以上的横向收尾与登顶
当我们终于爬到了 这一层时,跳表世界中的节点密度已经变得极其稀薄。根据之前的推导,整个跳表中,能够成功生长到 层或更高层级的幸存节点,其预期的总数量仅仅只有寥寥的 个。由于这些孤零零的高层节点已经是我们继续向左行走的全部潜在障碍物,这意味着即使我们倒霉透顶,把这一层以上所有的节点都踩一遍,我们在剩余旅途中的所有向左横移操作的次数期望值也被死死地限制在了 这一微小常数之内。
在解决了横向位移的顾虑后,我们剩下的唯一任务就是沿着当前的电梯井,继续向上攀升,直至抵达这座摩天大楼的真正物理楼顶。那么问题来了,一个包含了 个元素的跳表,它的预期最大物理楼层 究竟能有多高?
这需要一点微小的高阶概率计算。任凭一个普通节点,它的身高能够奇迹般地突破 层的概率是 。反过来说,它无法超越 层的概率就是 。由于系统中存在 个相互独立的节点,这 个兄弟没有一个人能够出人头地超越 层的联合概率就是 。
利用简单的互斥事件求逆逻辑,这座大厦中至少有一个超级节点突破了 层(也就是整个大厦的最大高度 大于 )的概率 ,自然就等于:
这看起来十分眼熟。这可以使用伯努利不等式!将该不等式 代入并进行反向放缩,我们得到:
通过更为复杂的负二项分布积分手段,严格证明了这座大厦的预期最大楼层高度 被锁定在一个确定的天花板之下:
这意味着,当我们已经身处 层时,我们抬头仰望,预期最多只需要再往上爬升 个阶梯,就能彻底登顶。
**总期望搜索成本
现在,是时候将所有碎片的账单汇聚在一起了。为了完成从茫茫跳表海中锁定任意一个目标,并反向退回原点的壮举,我们预期的总体步数开销构成为:
将前两项的分子合并:
由于我们在开篇已经论证过理想层高函数的核心机理是 ,我们将这个对数实体代回公式:
在这个数学方程式中, 仅仅是一个系统架构师预先设定的静止常数。因此,决定整个公式增长趋势的唯一变量就是包含了对数内核的 。在渐进符号体系下,常数项被抹去,这一结果完美地宣告:跳转表的查找开销被铁链般地锁死在了 这一复杂性级别上。
概率因子 的宏观调控与性能博弈
在彻底掌握了时间复杂度的数学命脉之后,一个实际的工程抉择摆在了系统架构师面前:既然概率因子 在公式中扮演着至关重要的调优角色,那么究竟应当如何取值,才能使系统达到最佳的工作状态?
这本质上是一场关于“计算时间”与“存储空间”的终极博弈。
-
如果我们极力压低 的数值,新节点向上晋升的门槛将变得极高。这会导致系统中绝大多数节点都是矮个子,从而大幅度削减了保存多层指针所需的内存体积(理论上平均每个节点挂载的指针数为 )。但硬币的反面是,由于缺乏足够的高架快车道,搜索过程中不得不进行大量的底层慢速爬行,导致搜索耗时增加。
-
如果我们肆意抬高 的数值,系统中将涌现出大量的高耸建筑。高架通道织密如网,搜索速度将得到极致的提升。然而,为此付出的代价是系统内存将被海量的指针对象所吞噬。
为了量化这种博弈,Pugh 在其论文中详细列出了一张性能影响矩阵比对表:
| 参数 p 的设定值 | 归一化搜索时间膨胀倍率 (即 L(n)/p) | 内存开销:平均每个节点的包含指针数 (即 1/(1−p)) |
|---|---|---|
| 1/2 | 1.00 | 2.00 |
| **1/e ** | 0.94… | 1.58… |
| **1/4 ** | 1.00 | 1.33… |
| 1/8 | 1.33… | 1.14… |
| **1/16 ** | 2.00 | 1.07… |
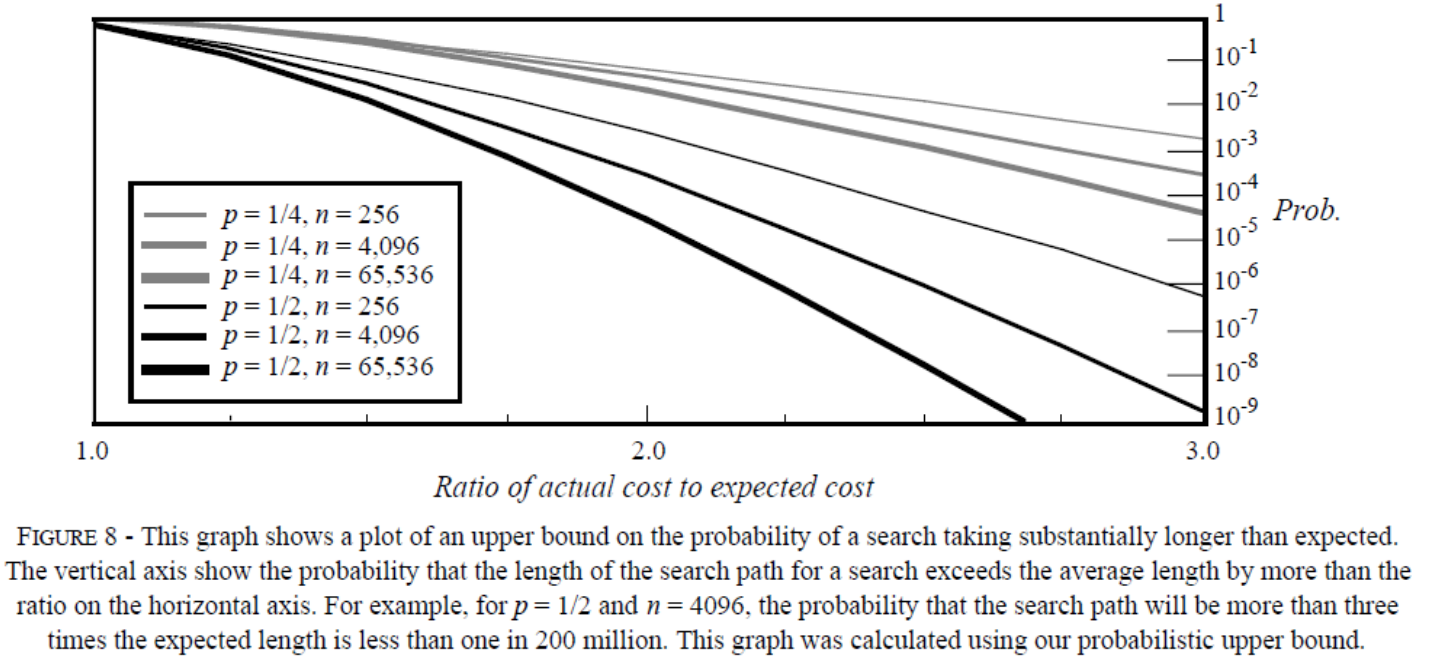
在这份详尽的实验数据面前,Pugh 给出了极其权威的工程指导意见:“如果你的业务场景对于偶然出现的个别搜索时间微小波动不敏感,那么为了追求时空效率的极致性价比,我强烈建议将 设定为 。只有在那些对每次查询响应时间的一致性有着近乎病态苛求的硬实时系统中,你才应该为了降低方差而妥协使用 。” 这一判断对后世的工业软件架构产生了深远影响,Redis 正是这一工程建议的忠实拥趸(其源码宏定义 ZSKIPLIST_P = 0.25)。
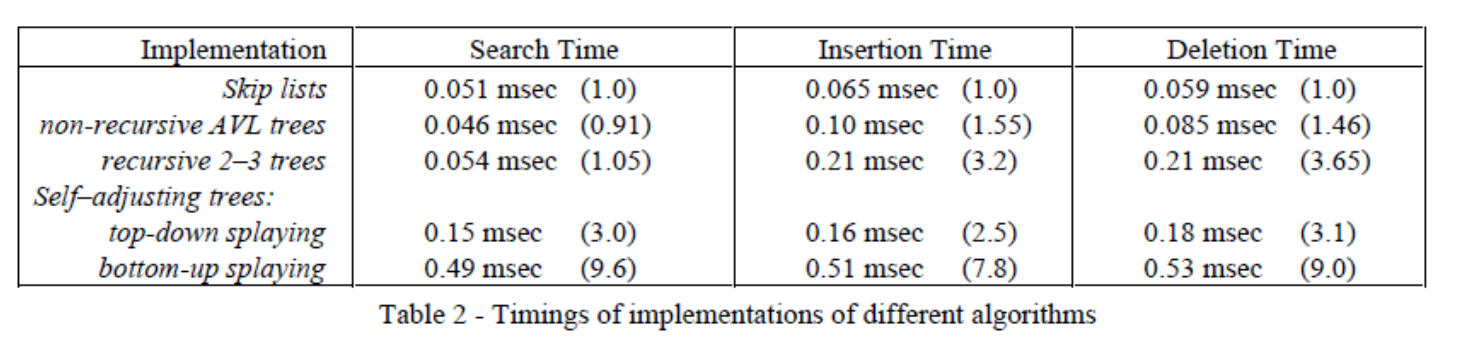
而在横向对比层面,在一个包含大量元素的测试集上,非递归实现的跳转表在执行毫无规律的随机 Search、Insert 和 Delete 操作时,其平均耗时参数甚至低于非递归 AVL 树,并以碾压的姿态击败了递归版本的 2-3 树以及各种花哨的伸展树(Splaying Trees)。
应用——LSM Tree
跨越了枯燥的纯数学推导,我们将视线转向跳转表在现代分布式海量存储领域的现象级应用——日志结构合并树(Log-Structured Merge-Tree,简称 LSM Tree)。在以 LevelDB、RocksDB、Cassandra 以及 HBase 为代表的全球顶尖 NoSQL 存储引擎内核中,跳表不仅没有缺席,反而化身为承上启下的系统咽喉要道。
硬件物理特性的天然鸿沟
想要透彻理解 LSM Tree 缘何被设计成今天这副模样,必须首先抛弃软件视角,去审视底层物理硬件——机械磁盘(HDD)与固态闪存盘(SSD)——的生理极限。无论是传统依靠磁头摇臂寻道的磁盘,还是依靠电子擦写重置块机制的 SSD,它们在面对“完全随机写入”与“严格顺序追加”这两种 I/O 模式时,所爆发出的性能差异宛如天堑。
根据基准穿透测试数据展示:
| 硬件存储介质类型 | 完全随机写入吞吐量 | 严格顺序追加吞吐量 | 性能落差倍率(概算) |
|---|---|---|---|
| 企业级 SAS 机械硬盘 (15K RPM) | 316 字节/秒 | 36.7 兆字节/秒 (36.7M/s) | 相差惊人的 ~116,000 倍 |
| 高性能 SATA 固态硬盘 (SSD) | 1,924 字节/秒 | 42.2 兆字节/秒 (42.2M/s) | 相差悬殊的 ~21,000 倍 |
在传统的关系型数据库(如 MySQL 的 InnoDB 引擎)所采用的 B+ 树模型中,数据的修改往往基于“原地更新”(In-Place Update)范式。这意味着当一条用户记录发生变更时,引擎必须在浩如烟海的磁盘块中精准定位到那个旧的数据页,将其加载到内存,涂改完毕后,再将这 16KB 的页面重新随机塞回到磁盘原处。在写入压力巨大的场景下,这种为了保持树状结构全局完美平衡而引发的疯狂随机 I/O,会瞬间将原本极其昂贵的企业级固态硬盘拖垮成一块毫无反应的废铁。
LSM Tree 架构的提出,本质上就是向这道物理性能鸿沟发起的一次降维打击。它的核心哲学极其粗暴且有效:在这个世界上,既然只有持续不断地向文件尾部写入追加(Append)才能压榨出硬件 100% 的带宽,那么我们就索性废除一切的原地修改与随机写! LSM 模型通过一种巧妙的内存缓冲与批量刷盘机制,将天马行空的随机写请求,硬生生地捏合成了一股不可阻挡的顺序写洪流。尽管为了维持这一壮举,引擎不得不在数据读取路径上忍受一定程度的性能衰退,但在今天这个每秒都在产生海量日志、点击和交易监控数据的写密集型(Write-Heavy)时代,这种性能置换被证明是一笔极其划算的买卖。
LSM 架构设计
一个标准的 LSM Tree 架构并非一棵孤立的数据树,而是由四大相互交织、各司其职的关键组件拼图组装而成的一套横跨内存与磁盘的生态管网体系。初学者可以将其想象成一个拥有多级沉淀池的水处理中心:
组件一:灾备黑匣子——Write-Ahead Log, WAL
当一条携带崭新键值对(Key-Value)的写请求叩开存储引擎的大门时,它绝不会被立刻送入主数据区进行复杂的排序融合。相反,引擎首先会用一种最不讲道理、但也最快的方式处理它:将这条原始的更改指令当作一行无格式的纯文本,极其粗暴地追加写(Append-Only)到磁盘上一份名为 WAL 的日志文件末尾,并立即触发系统的 fsync 指令将其固化到物理介质上。 WAL 没有任何检索查询的价值,它的存在只有唯一的使命:防患于未然的灾备恢复(Crash Recovery)。如果服务器在下一秒突然遭遇断电停机,内存中未来得及处理的瞬时数据将灰飞烟灭。但在系统重启后,只需让引擎像放电影一样将 WAL 文件中的指令重新从头重播一遍,那些看似遗失的数据就能完好无损地在内存中重生。
组件二:高速排序引擎——MemTable
在确认 WAL 已经安稳落盘后,数据才会被正式接纳进内存系统,写入到被称为 MemTable 的核心缓冲区中。在这里,数据的杂乱无章将被彻底终结,系统要求所有停留在这里的数据必须保持严格的字典序排列。 正是在这个处于内存风暴眼的组件中,跳转表(Skip List)以其并发优势闪亮登场。在 LevelDB 和 RocksDB 这种工业级 C++ 引擎的内核源码中,MemTable 的默认底层数据结构实现毫无例外地指向了 Concurrent SkipList(并发跳转表)。 为何不选用红黑树?因为红黑树为了维护脆弱的红黑节点颜色平衡律,一旦发生结构的局部旋转,必须依靠极其沉重的排他互斥锁(Mutex Lock)来封锁大面积的树干,这使得多线程的高并发写入沦为空谈。而跳转表各个节点在插入时依靠本地随机数独立生长,不同层级间的链表拼接彼此隔离,这使得架构师可以极其轻松地利用现代 CPU 的底层原子指令(如 Compare-And-Swap, CAS)实现无锁化(Lock-Free)的高并发结构。数据一旦进入这棵有序的跳表,不仅能够维持惊人的插入吞吐,还能轻易地对外提供 级别的实时点对点查询支持。
组件三:时光标本库——不可变内存表与 SSTable
MemTable 的容量并非无限,当它吸纳的数据体积触碰到配置的警戒线(例如 64MB 或 256MB)时,系统会果断下达封锁令,将其权限变更为只读的 Immutable MemTable(不可变内存表),同时在身旁新开辟一个空旷的 MemTable 来继续承接外面的写流量风暴。 随后,后台的搬运工线程会被唤醒,它要做的事情极其简单:直接从头到尾遍历这座已经被冻结的跳表,将里面严格有序的数据像倒模一样,原封不动地倾泻到磁盘上,形成一个崭新的数据文件——Sorted String Table(SSTable,排序字符串表)。由于跳表已经提前完成了最消耗 CPU 算力的排序工作,这个倾泻过程在磁盘视角看来,就是一场无比畅快淋漓的持续顺序 I/O 写操作,完美释放了硬件潜能。SSTable 一旦被烙印在磁盘上,就如同被封入琥珀的远古标本,永远无法被篡改。任何试图更新或删除已存在记录的操作,在此架构下,不过是重新走一遍流程,向系统再灌入一条带有更新时间戳的同名新记录,或者是贴上一张带有特殊删除记号的“墓碑”(Tombstone)便笺罢了。
组件四:收纳与湮灭机制——多级压实
随着岁月的流逝,磁盘上会堆积成百上千个不同批次刷写下来的 SSTable 文件,它们被粗略地划分为 Level 0, Level 1 直至 Level N 多个梯队。一个致命的问题开始凸显:用户的同一次修改尝试和删除操作可能散落在不同的文件中,当发起一次数据查询时,系统犹如大海捞针,不得不遍历大量可能包含冗余或已失效数据的文件,这被称为不可容忍的“读取放大”(Read Amplification)。 为了遏制这一趋势,引擎在后台会默默启动“清道夫”程序,即 Compaction(合并压实操作)。清道夫会定期抽取几本旧的 SSTable 账册读入内存,将它们执行多路归并排序。在这个过程中,它会无情地将那些带着墓碑标记的陈年旧账彻底抹除,将多次被覆盖的历史旧值丢弃,最后精炼提纯出一本更为紧凑、纯粹的全新 SSTable 放入更深层的归档室(更高的 Level 中)。这种以时间换空间、定期排毒的机制,是维持 LSM 系统长期健康运行的生命线。
读路径方案:布隆过滤器
在 LSM Tree 那优雅的写优化架构背后,隐藏着一个不得不面对的残酷现实:数据的读取路径变得极其漫长且泥泞。当业务方下达指令想要搜索某一个 Key 时,系统必须遵循严格的代际顺序进行溯源。它首先翻找最鲜活的 MemTable,若无果,则探寻被冻结的 Immutable MemTable;若仍未命中,便只能硬着头皮,从包含最新鲜刷盘文件的 Level 0 层开始,一层一层地向下挖掘所有被列为怀疑对象的 SSTable 历史文件库。试想一下,如果业务方试图查询一个在整个数据库中根本就不曾存在过的幽灵 Key,系统将会在毫无防备的情况下,把底层几十上百个关联文件全部从磁盘加载到内存扫视一遍。这种因无效查找而引发的无谓磁盘 I/O,是拖垮数据库查询时延的头号杀手。
为了在这个深不可测的查询迷宫中搭建一条逃生通道,存储架构师们在每个 SSTable 文件的末尾页脚处,挂载了一个极度精巧且消耗内存极低的概率数据结构武器——布隆过滤器(Bloom Filter)。 布隆过滤器就像是一个站在每个档案室门口的极其武断但又无比忠诚的门卫。当系统想要进入某个 SSTable 翻查目标 Key 之前,必须先将 Key 报给这位门卫。 门卫的判断准则极其特殊:
-
直断否决:如果门卫看了看 Key,摇摇头说:“这个人绝对不在我的房间里。”那么系统可以百分之百放心,直接越过这个文件走向下一个。由于节省了一次极其昂贵的磁盘寻道与加载,系统的查询效率在这一刻得到了质的飞跃。
-
容忍假阳性:如果门卫犹豫了一下说:“这个人大概、可能、也许在里面。”由于布隆过滤器存在数学理论上无法消除的哈希碰撞缺陷(假阳性 False Positive),门卫的肯定回答并不绝对靠谱。此时,系统别无选择,只能通过文件末尾附带的稀疏索引块(Sparse Index)定位到对应的具体磁盘扇区,进行一次真实的磁盘大搜查来验明正身。
通过将作为内存风暴眼的 Concurrent SkipList、作为持久化兜底方案的 WAL、作为数据归档库的 Immutable SSTable 以及作为免死金牌的 Bloom Filter 巧妙地融为一炉,LSM Tree 犹如一台精密的重工业机床,在极端的写入吞吐压力与可接受的毫秒级读取延迟之间,达成了一种震慑人心的工程艺术平衡。
应用——Redis
如果说 LSM Tree 将跳转表作为了其宏大流水线中的一个默默无闻的幕后齿轮,那么在风靡全球的轻量级内存缓存系统 Redis 中,跳转表则迎来了属于它自身最为高光和璀璨的独舞时刻。Redis 作为各种实时排行榜、限流器和延迟队列的绝对王者,其对底层有序数据结构的控制要求已经到了吹毛求疵的地步。它不仅要求能够在海量的游戏玩家积分数据中实现极速的成员增减、分数更新,还必须支持花样繁多的范围统计指令,例如获取积分介于两千到三千分之间的全体成员(ZRANGE)、逆向输出排名前十的大神榜单(ZREVRANGE),甚至需要在一瞬间直接报出某位指定选手的绝对全服排名(ZRANK)。
为了支撑起这种看似强人所难的多维度查询矩阵,Redis 的作者 Antirez 抛弃了任何单一数据结构的执念,创造性地采用了一种复合型双核引擎:一个 的哈希表用于完成从成员实体到其分数的一键映射锚定;而一座经过重度定制和深度魔改的跳表(Zskiplist),则负责承接所有基于分数排序和范围统筹的重体力活。
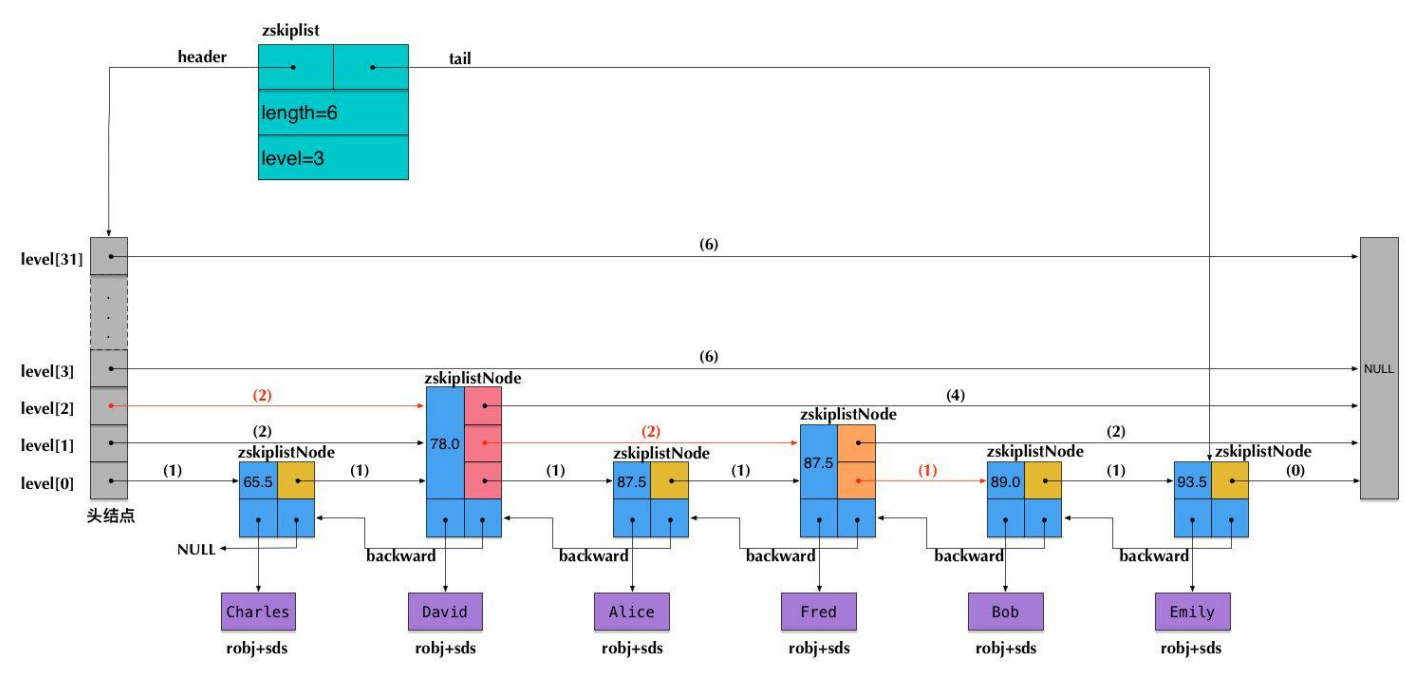
Redis Zskiplist 核心结构
1 | // Redis 对跳表的宏观控制常量约束 |
跨度与 O(log N) 排名计算
在原教旨主义的标准跳转表中,查找一个元素的时间复杂度确实能够被稳固地控制在 级别。但是,如果业务方的诉求并不是问“元素是否存在”,而是问“这个元素在所有数据中排在第几名(Rank)”时,原生的跳表架构就会瞬间陷入尴尬的僵局。因为普通的指针跳跃机制就像是一架蒙着窗户瞎飞的飞机,你虽然最终抵达了目的地,但你根本无从知晓沿途到底飞越了下方多少个村庄。为了获取精确排名,原始算法不得不采用极其原始的笨办法:顺着最底层(Level 0)的一般链表,从榜首第一名开始,如同点算羊群一般一个一个数过去,导致排名查询操作在数据量庞大时无可避免地退化为 的线性灾难。
Redis 作者凭借其天才般的工程直觉,在这架飞机的窗户上安装了一个特殊的计步器——这就是镶嵌在层级结构中的 span(跨度)属性。
- 跨度的物理刻度含义:在 Redis 的世界里,
span并不代表一段物理内存的距离,而是一个绝对精准的逻辑计数器。它精确地记录了当前这根长长的高空前向指针,在其飞跃下层空间的这段旅途中,实际上横跨跳过了多少个老老实实呆在 Level 0 底层公路上的基础节点。 - 实现 ZRANK 的破局之路:有了沿途所有
span值的记录辅佐,当 Redis 接到诸如ZRANK alice这样的查询名次指令时,情况发生了翻天覆地的变化。搜索游标依然像往常一样在多层通道中穿梭跳跃、寻找名为 “alice” 的节点。但与以往不同的是,系统在每次游标向右跨出一步时,都会顺手将所经过的那根forward指针上附带的span值累加到一个名为rank的局部累加器变量中。当游标最终准确降落在 “alice” 的面前时,这个累加器中所累积的数字总和,恰恰就是 “alice” 节点距离榜首起点所间隔的总节点数(即它的精确绝对排名)。
由于整个追踪和加和过程完全依附于标准的 下降路径,系统从头到尾连底层的具体元素面貌都不需要看清一眼,就兵不血刃地得到了排名结果。这种空间换时间的极致微创新,使得 Redis 毫不费力地在有序集合结构中实现了时间复杂度极其优越的排名统计。至于为此付出的唯一代价——在每次发生节点 Insert 或 Delete 破坏既有空间格局时,系统必须顺着 update 前驱记录数组,逐级重新校准和修补受牵连链路上的 span 数值,但这在 的修改深度限制下,相比起其带来的收益,完全是微不足道的开销。
后退指针的隐蔽线路与双向迭代
原生跳转表从设计基因上就是一个单行道系统。所有的高架通道均不可逆地指向右方,这种机制对于查找正向趋势极其友好。但在排行榜业务这种充满攀比与焦虑的应用场景中,用户不仅热衷于查看最高分,更加热衷于快速翻阅倒数的后十名(ZREVRANGE 指令)或是向后逆推排位。
面对这种反方向的查询洪流,单纯的单向跳表显得束手无策。然而,如果强行在所有的高层跳跃通道中也全部引入倒挡(增加逆向的高层后退指针),又会因为需要维护巨量复杂的反向映射关系而使代码变得臃肿不堪,并且让内存占用率急剧飙升。
Redis 在这里做出了一次极具实用主义色彩的精妙取舍妥协。在 zskiplistNode 的定义中,我们能够清晰地看到一个形单影只的 *backward(后退指针)孤零零地独立在核心层级数组之外。请务必深刻理解这一点:在 Redis 这座宏伟的跳表大厦中,后退指针是一项极其特殊且唯一的底层特权,它仅仅且只被赋予给了最贴近地表的 Level 0 基础链表。
这种“上层单向高速跳跃,底层致密双向蠕动”的半退化结构组合,展现出了令人惊叹的复合战力:
- 当系统接到需要抓取任意一段倒序名次区间的指令时,算法主体首先全权接管,利用上层那张密不透风的高速单行道网,仅需微小的对数时间开销,便如同精确制导导弹一般瞬间扎入目标区间的末端尾部。
- 一旦游标成功降落触底,高层的跳跃使命宣告终结。系统立刻切换引擎,利用那个隐蔽的底层后退通道(
backward指针),像倒带一般沿着 Level 0 这条坚实的双向链表向后轻松回溯。每一次回退读取的操作成本,仅仅是微不足道的线性常数级 。
这种将粗线条的大范围高空快速跳跃与细颗粒度的底层短距精准回退无缝衔接的混合查询体系,不仅在内存控制上做到了极度的克制,更在逆序检索的性能响应上取得了令人瞩目的辉煌战绩。