
ADS-03:伸展树
二叉树的计数与枚举
在探究如何优化二叉搜索树之前,必须首先解答一个基础的组合数学问题:给定 个节点,究竟可以构成多少种拓扑结构互异的二叉树?这一问题不仅决定了二叉树状态空间的大小,也从根本上限制了任何树形数据结构在极端情况下的退化可能 。
通过对栈操作序列的观察,可以直观地建立起二叉树形态与操作序列之间的双射关系。在深度优先遍历或树的动态生成过程中,每一次向左下方的深入都可以视作一次“入栈”,而每一次向父节点或右子树的回溯则视作一次“出栈”。对于包含 个节点的二叉树,其生成过程必然包含 次 Push 和 次 Pop 。
正如图中序列所示,不同的 Push 与 Pop 组合直接映射到不同的二叉树形态。例如,针对特定的节点数,可以记录不同形态的二叉树对应的有效操作序列:
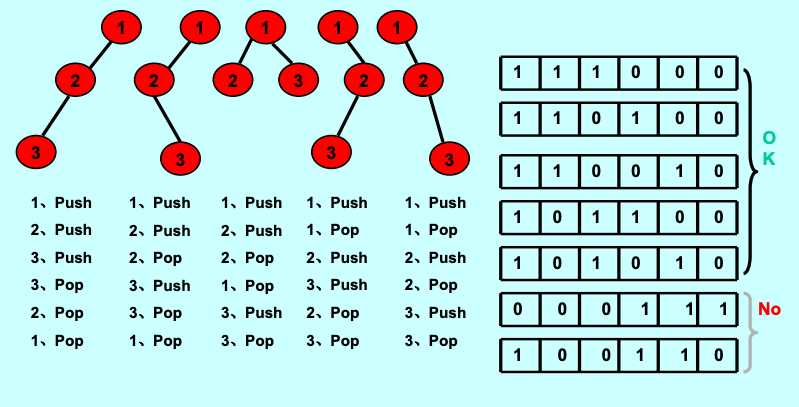
上述序列揭示了一个核心约束:在任何时刻,累积的 Pop 操作次数绝不能超过累积的 Push 操作次数,否则就意味着试图访问空树的父节点,这在物理上对应于非法的树结构 。这种带有严格前缀非负约束的序列生成问题,是许多经典组合问题的同构表现形式。
卡塔兰数与同构问题
上述栈排列问题可以被完美地抽象为经典的“网格路径问题”(假设我们需要在一个 的二维网格中,寻找从左下角起点走到右上角终点的最短路径。在移动时,只能沿着网格线向右(对应 Push 操作)或向上(对应 Pop 操作)移动 。
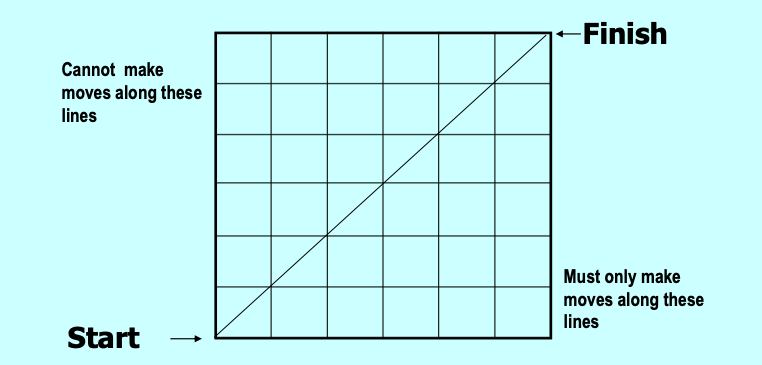
如果仅仅是寻找最短路径,答案显然是 ,即在总共 步中选择 步向右。然而,为了满足前缀非负约束(即任何时刻向上的步数不能超过向右的步数),我们必须引入一条严格的边界线:对角线。路径在任何情况下都不能越过主对角线,必须且只能在对角线及以下的合法区域内移动 。
路径的字符串与括号表示
如路径示意图所示,一条合法的路径可以被等价编码为不同的符号串 :
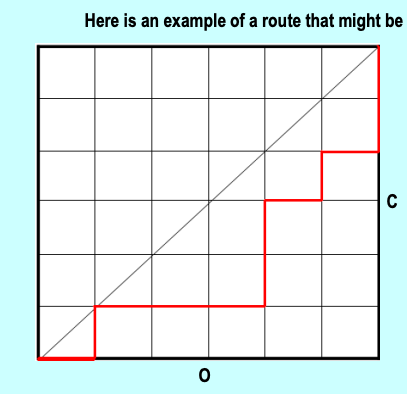
-
字符序列表示:
OCOOOCCOCOCC(其中O代表横向的 Open/Push,C代表纵向的 Close/Pop)。 -
括号嵌套表示:
()((( ))()())。在这个表示中,每一个左括号(对应向右走一步,右括号)对应向上走一步。 对角线不被穿越的约束,完美等价于括号字符串中“任何前缀里的右括号数量都不超过左括号数量”的规则 。
翻转原理与解析推导
为了计算出这样合法路径的精确数量,普遍采用反射原理 。假设存在一条越过了主对角线的非法路径,这意味着该路径必然与对角线上方一单位平移的线(即方程为 的线)产生交点。
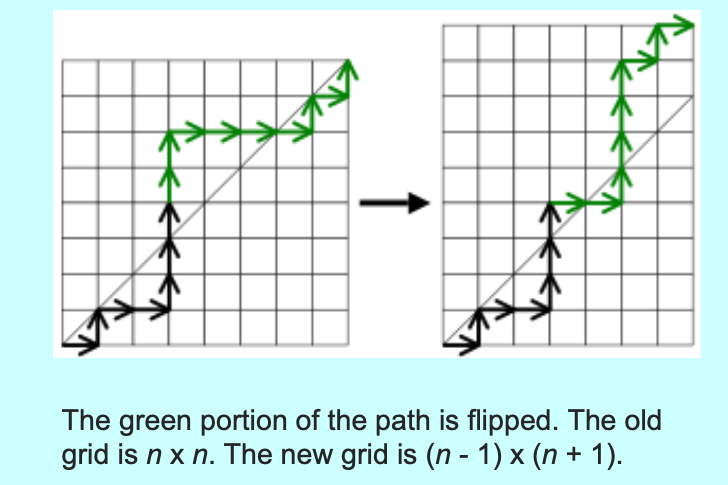
找到该路径与 的第一个交点。将该交点之后的路径部分(即标记为绿色的部分)关于 这条直线进行对称翻转 。 翻转前,原路径的终点是 ;翻转后,横纵坐标会发生镜像反转和偏移,新的终点将无一例外地落在 处。由于从 到 的任何一条单调路径都必然穿过 (因为终点在该线上方),这就建立了一个完美的双射:从 到 的所有非法路径,与从 到 的所有无约束路径一一对应 。
到达 的所有路径数为 或 。因此,合法的非越界路径总数即为总路径数减去非法路径数,这就引出了卡塔兰数的经典减法定义式 :
二叉树生成函数
为了从更严格的代数角度推导这一结果并计算 个节点可以构成的二叉树数量,我们可以利用生成函数这一强有力的工具。设 为包含 个节点的互异二叉树的数量,我们定义生成函数 如下 :
一棵非空的二叉树总是由一个根节点、一棵包含 个节点的左子树和一棵包含 个节点的右子树构成。根据乘法原理,给定节点数的二叉树种类数满足卷积递推关系 :
将这一递推关系转换为生成函数的代数方程,由于右侧是卷积形式,它对应于生成函数自身的平方。因此,考虑到根节点占据的一个 ,我们得到源文件中核心的非线性泛函方程 :
这是一个关于 的一元二次方程:。根据求根公式,解得 :
(这里舍弃了正号解,因为当 时,正号解会趋于无穷,而根据定义 ,负号解在洛必达法则下收敛于 1,符合物理意义 )。
为了从这个闭式解中提取出系数 ,需要利用广义二项式定理对平方根项进行泰勒级数展开 :
将其代回 的表达式中,并消去常数项与分母中的 ,提取多项式系数,推导如下 :
通过进一步展开组合数 并化简双阶乘,最终可以精准提取出第 项的系数 :
运用斯特林公式对阶乘进行渐近分析,可知该序列的增长率极为惊人,其渐近界近似为 :
指数级的增长意味着即使节点数 不大,二叉搜索树可能退化出的形态也如天文数字般庞大。这也从侧面印证了为何我们需要精心设计的数据结构来规避那些导致退化的树形态。
卡塔兰数的历史与应用
序列 在数学史上具有极为独特的地位,它以比利时数学家欧仁·查理·卡塔兰的名字命名,但其历史渊源却横跨欧亚大陆 。
明安图与欧拉的独立发现
在现代组合数学文献中,卡塔兰数被认为是无处不在的,但其首次见诸文献则要追溯到18世纪的中国清代。蒙古族数学家、天文学家明安图在其历经三十年写就的微积分先驱著作《割圜密率捷法》中,在世界上最早使用了卡塔兰数 。
不同于西方通过离散组合问题发现该序列,明安图是在研究三角函数的无穷级数展开时,通过几何建模推导出了包含卡塔兰数的连分数与级数系数 。例如,在其关于 的推导中,明确给出了如下恒等式 :
明安图不仅写出了级数展开,甚至推导出了卡塔兰数序列本身的递推公式,这一成就远远早于欧洲同行,尽管理解其背后的组合意义是在一个世纪之后 。
在欧洲,莱昂哈德·欧拉在1751年也独立发现了该序列,当时他正试图计算一个 边形的凸多边形,通过不相交的对角线将其完全划分为 个三角形的总方法数 。直到 1838 年,卡塔兰在研究括号匹配问题时再次定义了该序列,并给出了更为优雅的公式,后世因此将其正式命名为卡塔兰数 。
帕斯卡三角形中的中心列分布
卡塔兰数的减法公式 ,在帕斯卡三角形的中央列数据中表现得非常直观 。如源文件表格所示,中心列数据(即 )减去其相邻列数据(即 ),便完美地生成了卡塔兰数序列:

| 深度 2n | 中心列项 (n2n) | 相邻列项 (n+12n) | 相减差值 (Cn) |
|---|---|---|---|
| 2 | 2 | 1 | |
| 4 | 6 | 4 | |
| 6 | 20 | 15 | |
| 8 | 70 | 56 | |
| 10 | 252 | 210 |
括号问题与矩阵链乘
除了树的形态枚举,卡塔兰数还直接决定了以下经典计算机科学问题的解空间:
1. 括号匹配问题 如前所述,卡塔兰在1838年解决了合法安排 对括号的问题。一个合法的字符串必须满足:开闭括号数量相等;且从左侧数起,任何位置的右括号数量不得超过左括号。 例如,()()()、(()())、()(()) 是合法的,而 )())(( 则是非法的。通过穷举可知,当 时,恰好存在 种合法序列 。
2. 矩阵链乘优化 在计算 个矩阵的乘积 时,由于矩阵乘法满足结合律但不满足交换律,计算顺序的不同(体现为加括号方式的不同)会极大地影响标量乘法的总计算量 。这等价于拥有前序遍历序列 的二叉树中,能够获得多少种不同的中序遍历排列。 设 为计算 个矩阵乘积的不同加括号方式数量,存在如下规律 :
-
: 以及 ,共 种。
-
: 共 种。 通项满足卡塔兰卷积: (其中 ) 。
理解了由卡塔兰数主导的二叉树极端退化潜力( 的树高),我们就深刻认识到引入树形自平衡机制的紧迫性。
AVL树与B-树
在信息组织算法的发展史上,苏联数学家 G. M. Adelson-Velskii 和 E. M. Landis 于 1962 年正式提出了 AVL 树 。作为人类历史上第一棵自平衡二叉搜索树,AVL树提出了严格的平衡因子约束:任何节点的左右子树高度差绝对值不得超过1 。
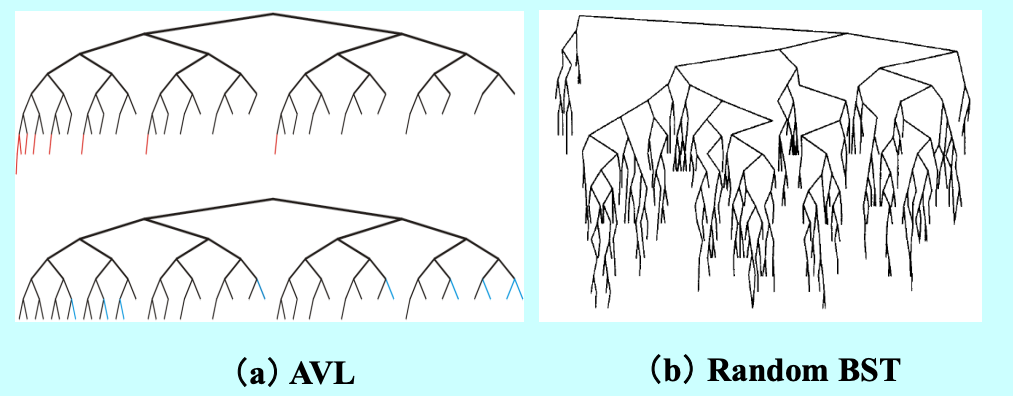
通过对比高度为 的树的形态可知,随机生成的 BST 往往伴随深层的偏斜分支,而 AVL 树则始终保持接近完美的层级饱满度,其高度被严格限制在 。
局部失衡与传统的四种旋转
在 AVL 树中,插入或删除节点可能破坏高度平衡属性。按照导致失衡的节点在结构上的相对位置,传统的重平衡被分类为四种独立的情况 :
-
Left Left Case (LL):需要进行一次单次右旋。
-
Right Right Case (RR):需要进行一次单次左旋。
-
Left Right Case (LR):需要先做一次左旋,再做一次右旋。
-
Right Left Case (RL):需要先做一次右旋,再做一次左旋。
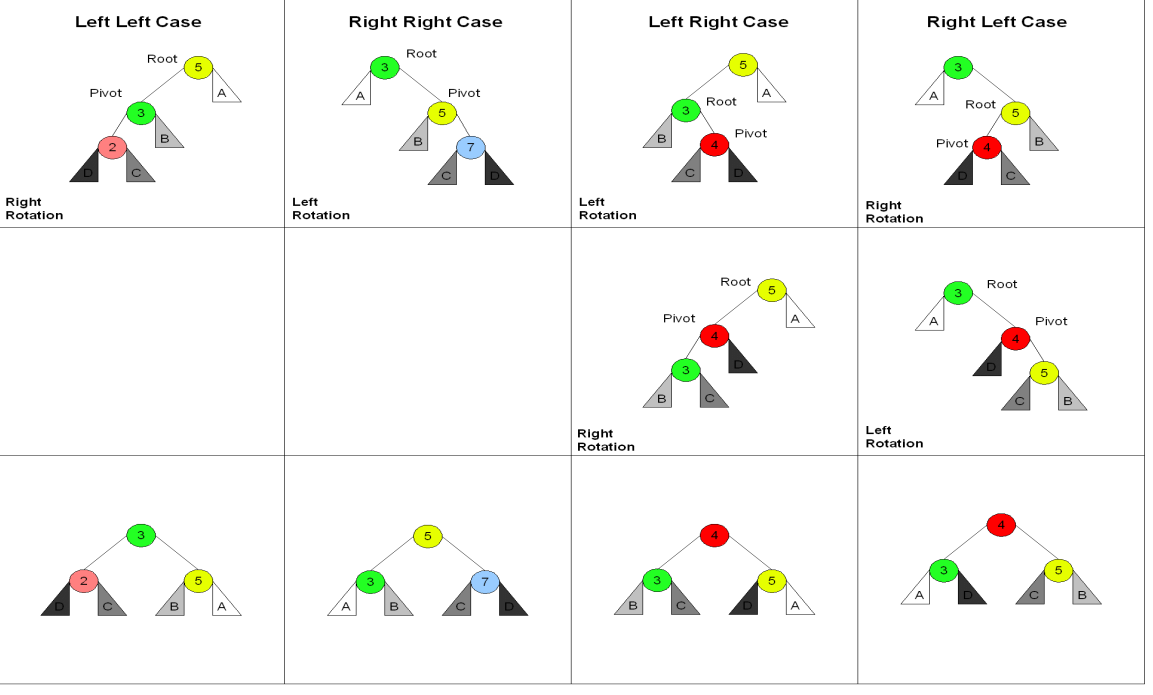
这种 Case-by-Case 处理方式(如 Root 被降级,Pivot 提拔为新根),虽然有效,但在代码实现上充斥着大量的条件分支逻辑,极易出错且不够优雅 。
3+4 重构算法
为了克服传统多次旋转逻辑的繁琐,可以引入 3+4 重构 。该算法看破了所有旋转的表象,直接从遍历序列的拓扑不变量入手进行物理替换。
设 为插入/删除后发现的最低失衡节点。我们考察构成失衡路径的祖孙三代节点:(祖父)、(父亲)、(孙子,即 )。 由于这三个节点属于同一棵二叉搜索树,它们必然具有严格的相对大小。我们按照中序遍历次序,将这三个节点重新命名为 ,使得满足 。
这三个节点作为内部骨架,向外伸展必然连接着总共互不相交的四棵(可能为空的)子树。同样按照中序遍历次序,将这四棵子树重命名为 。因为中序遍历保持单调递增属性,原始树的局部拓扑严格满足:
等价变换与树结构重塑: 接下来,算法直接将原先以 为根的整个子树 连根拔起,替换为一棵凭空构建的全新子树 。构建这棵新子树的规则极为统一且固定 :
-
强制将居中的 提升为新子树的根节点()。
-
将 作为 的左孩子(),将 作为 的右孩子()。
-
按顺序挂接四棵子树: 的左子树为 (),右子树为 (); 的左子树为 (),右子树为 ()。
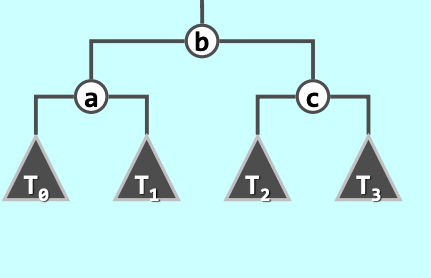
通过这一次 复杂度的原子级拼装重组,不仅失衡被彻底消除,更重要的是,新树的中序遍历依然严格是 。它完美覆盖了传统的 LL、RR、LR、RL 四种情境,是空间与逻辑的极致抽象 。
B-树及其变体
当搜索树的规模庞大到必须存储于诸如磁盘或磁鼓这种外存设备时,二叉树的层级结构会导致过多的页面I/O。R. Bayer 和 E. McCreight 于 1971 年提出了 B-Trees,通过允许节点拥有多个分支,将树形变得极度宽广 。
在此框架下,阶数为 的B树允许节点拥有至多 个分支。源文件中特别强调了低阶的特例 :
-
时,即为著名的 2-3-树(由 John Hopcroft 提出)。各内部节点的分支数只能是 2 或 3,含有的 key 数量为 1 或 2。
-
时,为 2-3-4-树。分支数可能为 2、3 或 4,key 数量为 1、2 或 3。 红黑树实际上就是一棵等价的 2-3-4 树的二叉实现,其中红色节点表示与其父节点在 B 树中处于同一个逻辑节点内,而颜色翻转机制则完美对应着 B 树中的节点分裂 。
伸展树
尽管 AVL 树和红黑树提供了可靠的 最坏情况边界,但它们需要维护额外的状态位(平衡因子或颜色),且重平衡逻辑在系统开销中占据了一定比例。更为致命的是,严格平衡的结构对数据的访问模式毫无感知 。
在操作系统内核、内存管理以及缓存系统中,信息处理过程屡见不鲜地展现出局部性原理:刚被访问过的数据以及其附近的数据,在极大的概率下会很快地被再次访问 。例如,Pfaff 在 2004 年的论文中通过对 Mozilla 1.0、VMware GSX Server 等实际负载的剖析,利用地址空间和操作次数的散点图证明了访问的高度集中与成簇分布 。
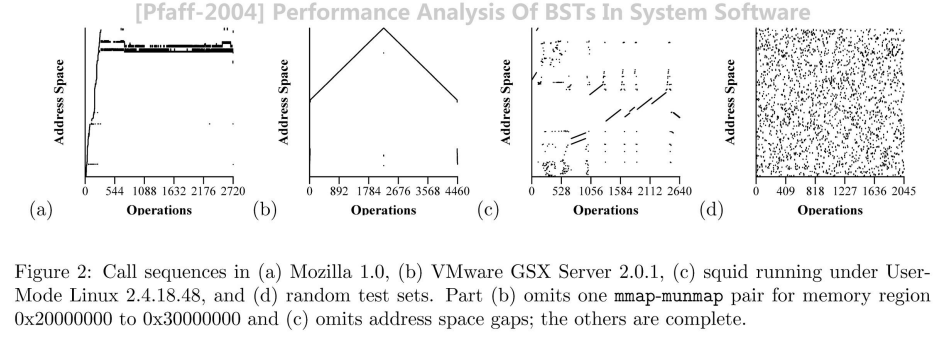
对传统的 AVL 树进行连续 次高度相关的查找(),总时间仍将不可避免地达到 。我们能否利用局部性特征来加速查找过程?
Daniel Dominic Sleator 和 Robert Endre Tarjan 在 1985 年给出了革命性的答案:伸展树。这种自适应二叉搜索树不需要显式的结构平衡约束,而是依赖一种简单的重构启发式算法——伸展。仿照自适应链表将访问节点移至前端的做法,伸展树规定:节点一旦被访问,随即将其调整到树根 。
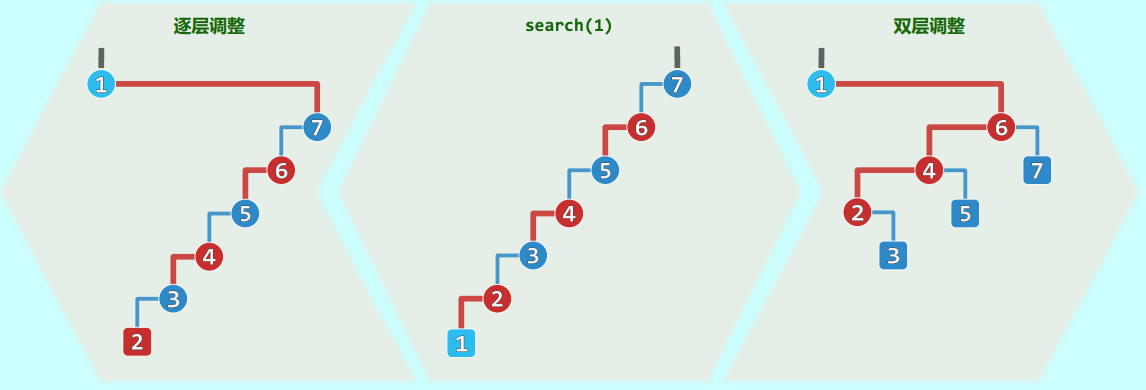
逐层单旋的陷阱与最坏情况
然而,如何实现“将目标节点推送至根”是一门极具讲究的艺术。早期的直观思路是逐层伸展 。 当节点 被访问后,与其说“推”,不如说“爬”。我们只需反复对其与其父节点 执行普通的单旋操作:如果 是左孩子,就执行 zig(p);如果是右孩子,就执行 zag(p),一步一步自下而上,直到 抵达树根 。
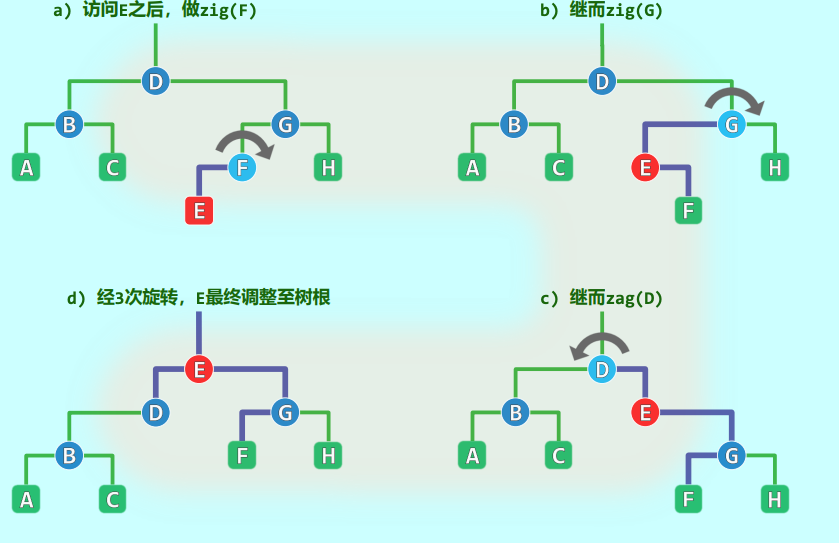
Allen 和 Munro 的研究表明,这种简单的逐层调整启发式极其低效。考虑一个最坏情况: 假设初始结构是一条向左严重倾斜的单链(例如插入顺序为 )。如果此时顺序执行 search(1), search(2), search(3), search(4), search(5):
- 当
search(1)时,1 通过逐层zig被推到树根,但在这个过程中,原来的链表结构只是像算术级数一样周期性地错位了,其余节点仍然拖着长长的尾巴 。
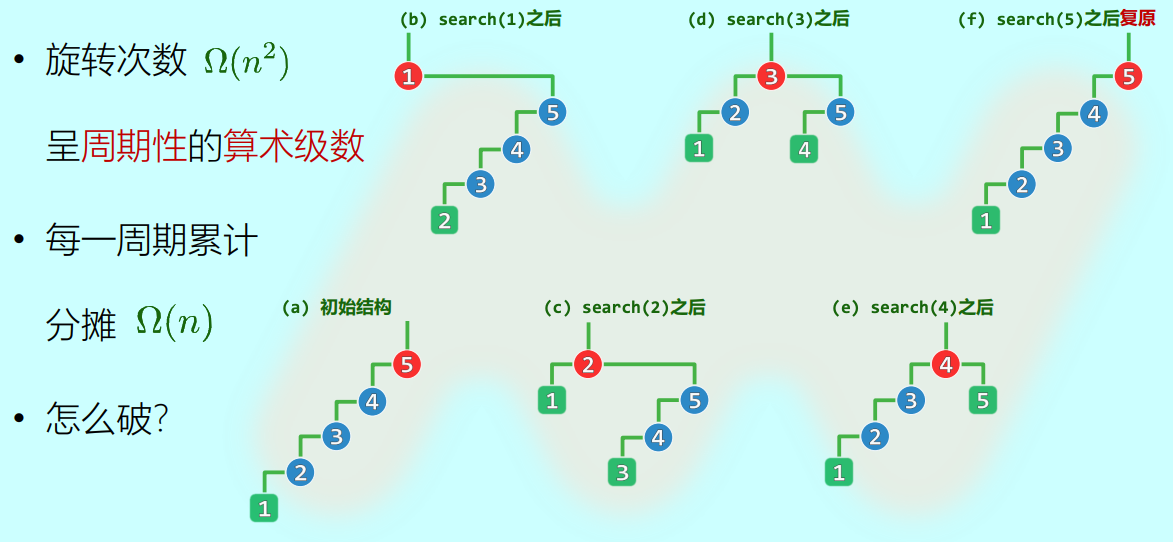
- 经过连续 5 次这样从最深处的查找,旋转次数将呈现 的复杂度 。 这意味着,每一周期的分摊时间成本竟高达 ,且这种最坏情况会持续发生,导致该启发式彻底失效 。怎么破局?
双层伸展
Sleator 和 Tarjan 构建伸展树的精髓在于:向上追溯两层,而非一层 。在决定如何旋转时,算法需要反复考察祖孙三代的相对位置结构:设 为当前被访问节点,,。根据这三者的拓扑关系,算法精心设计了成对的两次旋转操作(双层伸展),令 上升两层成为子树根 。
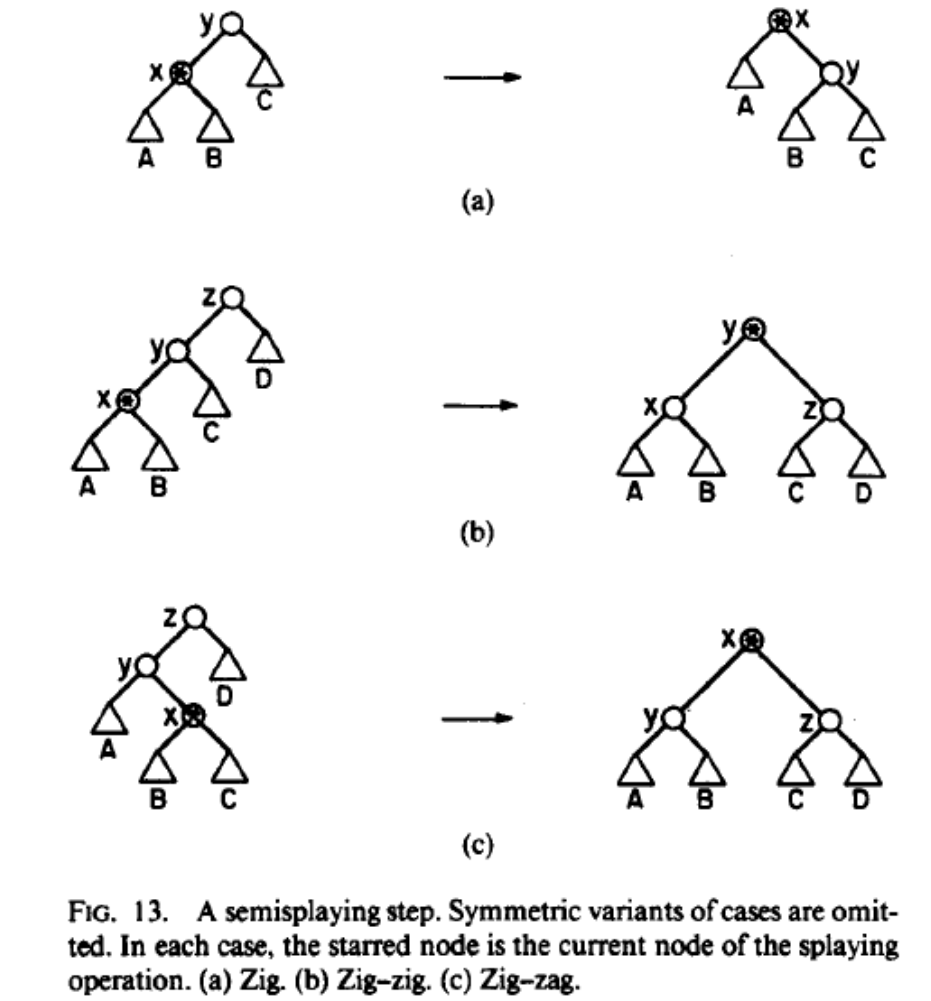
情况 1:zig-zag / zag-zig(异向拐弯) 如果 是左孩子的右孩子(zig-zag),或者右孩子的左孩子(zag-zig),此时 按照中序遍历次序居中 。
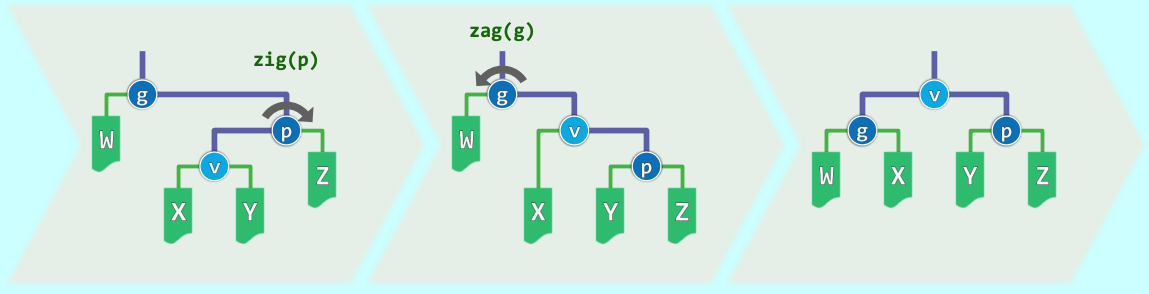
- 此时算法执行一次底层旋转(例如对 和 ),紧接着再对 和 执行一次旋转 。
- 这种调整模式的实际效果与连续两次逐层调整别无二致,虽然看起来平淡无奇,但它将 推上了祖父的位置,并均衡了子树 。
情况 2:zig-zig / zag-zag(同向直线) 这是 Splay Heuristic 能够打破 魔咒的核心创新 。如果 是左孩子的左孩子,或者右孩子的右孩子。
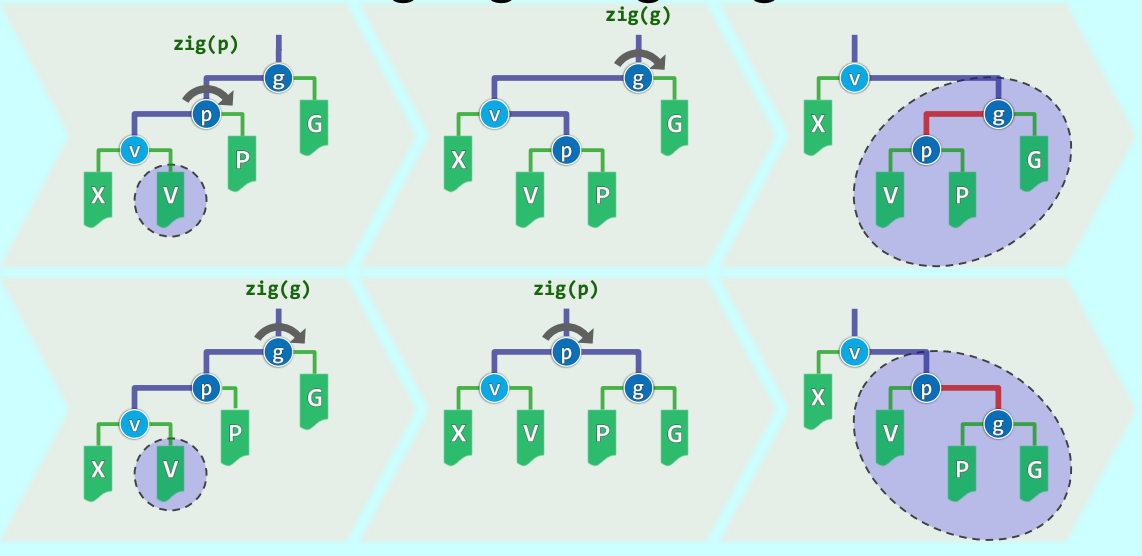
- 传统逐层调整会先转 和 。而在伸展树中,必须先转 和 ,然后再转 和 。
- 即先执行
zig(g),再执行zig(p)(或全为 zag)。 - 折叠效应:在图解中可以清晰看到,按照这种独特顺序旋转后,原本位于同一侧深度的长链结构,如同含羞草一般发生了“折叠”。由于优先旋转上层的祖父节点,对应路径的长度随即折半 。 当针对单链结构底部的节点
search(1)后,经过双层调整,原本深不可测的退化链条被极大地宽泛化。由于长链不断折半,最坏情况被彻底杜绝,这就是伸展操作分摊能够将时间压低至 的物理原因 。
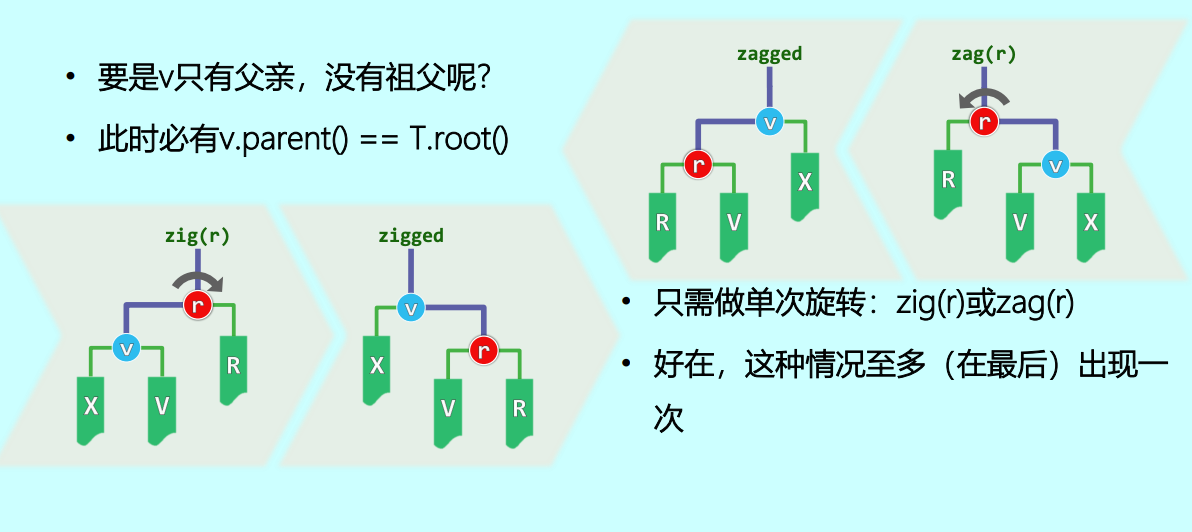
情况 3:zig / zag(单旋收尾) 如果 爬升到最后,发现只有父亲 没有祖父 (即 已经是整棵树的根 ),那么只需进行一次简单的单旋 zig(r) 或 zag(r) 将 推到最终的根部。这种情况在每一次伸展过程中至多出现一次 。
(还有一种名为半伸展(Semi-splaying)的变体。在 zig-zig 情况下,旋转一次后 并不继续上升,而是让焦点转移到其父节点,仅把 推进一半深度。这减少了重构的操作量且保持了渐进效率,但实际实现复杂度的增加以及合并分离操作的困难,使得全伸展依然是主流方案 )。
伸展树的算法设计与 C++ 实现
为了最大化代码复用,伸展树 Splay<T> 是由标准的二叉搜索树模板 BST<T> 派生而来的 :
1 | template <typename T> class Splay: public BST<T> { |
核心 splay 算法的实现细节
splay 方法是一个 while 循环,只要当前节点拥有曾祖父级别的上升空间,就会反复自下而上触发双层伸展操作 。
1 | template <typename T> |
这段代码对 zig-zig 分支中的指针操作尤为精妙:首先将 的右子树托付给 的左侧,将 的右子树托付给 的左侧,然后让 成为 的右孩子, 成为 的右孩子。彻底打破了原始直链,完成了向上的双重跃迁 。
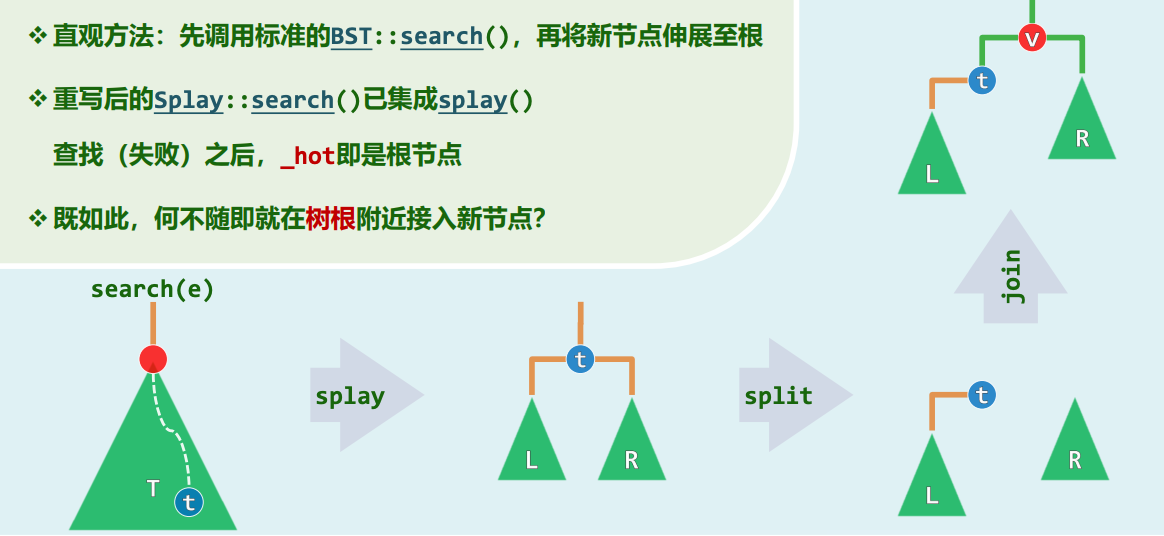
接口重写与 hot 机制
伸展树的查找 search 绝非静态的只读操作,而是强力修改树拓扑的驱动源。在 search 内部,首先调用基类标准的 BST::search(e) 来定位节点。不论查找是成功命中,还是失败跌落到底部,BST 中记录最后访问节点位置的全局隐式指针 _hot 都将被唤醒 。
1 | template <typename T> |
正因为任何一次搜索都会将相关节点顶出水面(移至树根),伸展树的 插入与 删除逻辑摒弃了传统 BST 那种深入叶子节点操作的笨重模式,转而利用根部的树分裂与树合并 。
插入重构(Split): 传统的插入需查找到叶子后创建节点。既然 Splay::search() 已集成 splay() 功能,若查找失败,_hot 节点(恰为待插入位置的前驱或后继)已被提升至根部 。 何不随即就在树根附近接入新节点?以新节点 为新的超级树根,将原有被伸展到根部的树按大小比较,从根部切割(split)为左子树 和右子树 。将 与 直接作为 的左右分支接入即可。这彻底避免了从根向下穿越的往返开销 。
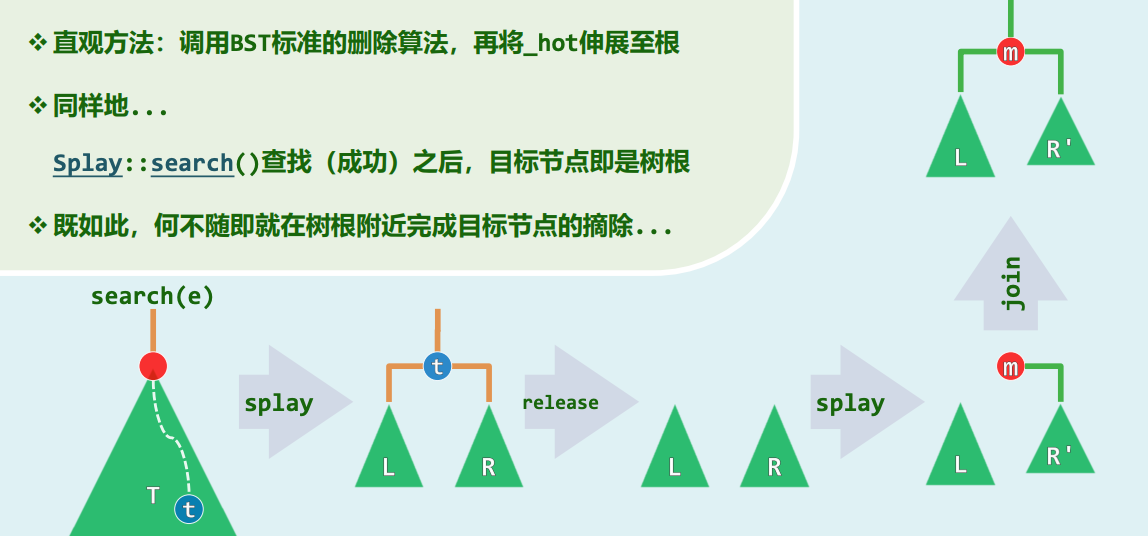
删除重构(Join): 删除机制运用了相同的哲学。当 search(e) 命中时,目标节点刚好被上浮并占据了整个树根的位置。此时,我们直接从根部释放(release)该目标节点,整棵树随之断裂为互相孤立的左右两棵子树 和 。 随后只需执行合并操作(join):在 中寻找最大值元素 。寻找 的过程同样会触发伸展,使得 成为 树的新根。由于 是全 中的最大者,它必定不含有右子树。此时,只需将孤立的右树 挂接为 的右孩子,全树便无缝愈合 。
综合评价与势能分析
从工程应用的角度,伸展树极具吸引力。它无需在节点中额外记录高度或平衡因子(如 AVL 的 或 Red-Black 的颜色位),编程实现简单且空间利用率更高 。虽然它无法提供对单次操作最坏情况 的严格阻断(故不适用于硬实时或对时延抖动极其敏感的安全级控制系统),但其在长序列操作上的表现极为抢眼 。
基于势能方法的分摊复杂度证明
Sleator 和 Tarjan 运用势能方法给出了伸展树分摊时间为 的优美数学证明 。 证明过程中,人为地给树中的每一个节点 赋予一个任意权重 (通常为 1)。并定义:
- 大小函数 :表示以 为根的整棵子树中所有节点权重的总和 。
- 秩函数 :定义为大小的对数,即 。
- 系统总势能 :全树所有节点秩的总和 。
这里的势能 充当了一个无形的“银行账户”。对于极度不平衡的退化树(如长链),越往下的节点 下降极为缓慢,导致总势能 极高;而对于平衡的树,各节点 呈指数级衰减,使得总势能极低 。 任何一次树操作的“分摊成本”(Amortized Cost,)被定义为其“实际时间开销”()加上“系统势能的变化量”() 。即如果旋转耗费了真实时间但让树变得更平衡(势能下降),多余的耗时被势能释放补偿;反之则需预缴势能存入账户。
根据源材料的核心推导,设单次旋转的实际时间为 1。分析每一次 splay step(令旋转后的秩为 ):
- 对于 zig 步骤,由于仅 和 的秩改变,其分摊成本被放缩并绑定为 。
- 对于 zig-zig 步骤,涉及到 三者的变化,通过严密的放缩推导(利用 和 秩的置换以及对数函数的凸性),其分摊成本被极其精妙地绑定为:(注意这里去掉了 ) 。
当我们把一次完整的伸展操作(连续执行多次双层旋转外加最后可能的单旋)的所有步骤叠加时,其分摊成本构成了望远镜级数 。所有中间节点的 项完全抵消,最后只剩下:
由于最底部的叶子节点其秩至少为 0,且整棵树树根的秩为 ,故无论最坏情况下发生了多么复杂的长链翻卷,单次伸展操作的分摊耗时绝对不会超过 。这就在数学上完成了 分摊时间复杂度的终极证明 。
动态最优性与工作集定理
势能方法中的权重分配具有高度的灵活性,这赋予了伸展树极为强大的适应能力。 如果我们为全树节点分配均匀权重 ,则势能初始值与结束值之差被限制在 范围内。由此可推导出经典的平衡定理:在一个 节点的伸展树上执行 次操作,总耗时不过是 。当操作序列极长时(),伸展树的整体效率等同于任何严格静态平衡的搜索树 。
更进一步,若根据节点上次被访问的时间周期来倒推分配权重,便可证明工作集定理 。该定理指出,如果要访问目标元素,所需的分摊时间与 成正比,其中 是自从上一次访问该元素以来,所访问过的不同元素的总数(即工作集的大小) 。 如果 (系统的活动数据即工作集仅有 个),虽然整棵树中容纳了 个海量数据,但是这 个热点节点将始终盘旋在树冠顶端,对它们的连续查找分摊成本将自适应地缩减至 的常数级,且无需显式地去配置何种热点追踪机制 。 任何由 次热点查找组成的序列,只需付出 的时间代价 。