概率路径
概率路径与条件概率路径
流匹配 Flow Matching 的起点是 概率路径 Probability Paths。概率路径是随时间变化的分布序列 (pt)0≤t≤1,用于把简单先验分布连接到真实数据分布。
实际训练中无法直接观测 pdata,也无法直接构造 pinit 到 pdata 的全局路径。
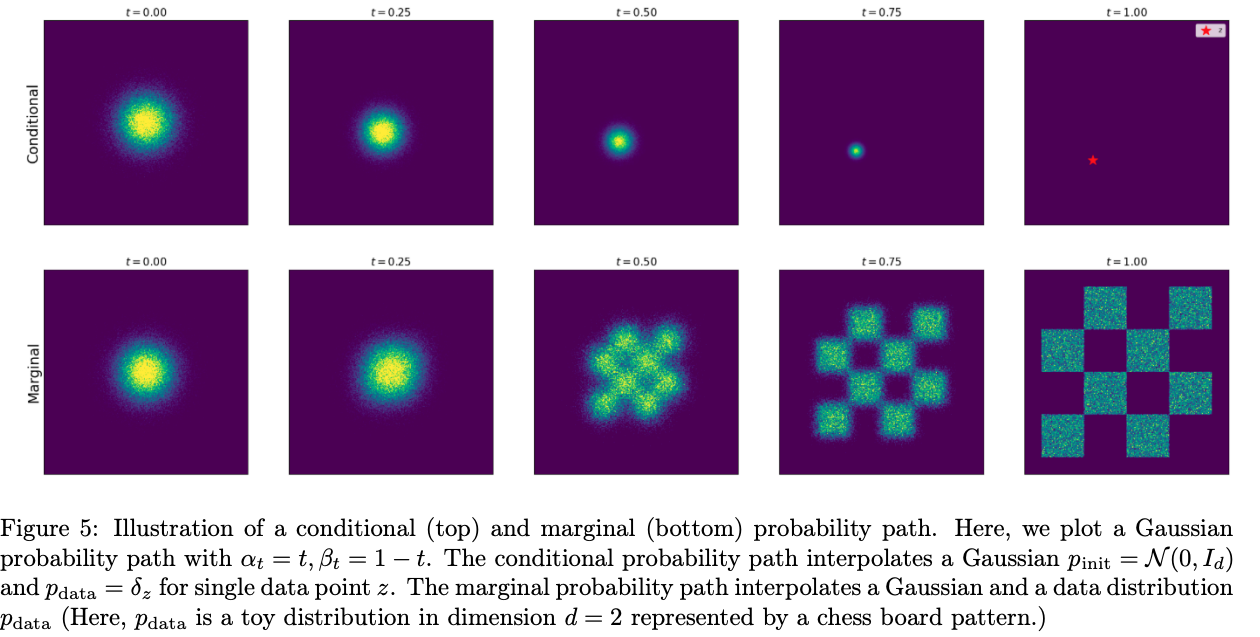
可行做法是对每个样本 z∼pdata 构造从噪声到该样本的 条件概率路径 Conditional Probability Path pt(x∣z),并满足:
- t=0 时为初始噪声分布,通常设为 p0(⋅∣z)=pinit=N(0,Id)。
- t=1 时塌缩到数据点 z,即 p1(⋅∣z)=δz,其中 δz 是以 z 为中心的 Dirac delta 分布。
这样即可定义从噪声到样本的条件演化路径。
边缘概率路径
给定条件路径 pt(x∣z) 后,可通过边缘化得到 边缘概率路径 Marginal Probability Path pt(x):
pt(x)=∫pt(x∣z)pdata(z)dz
边缘分布是所有条件分布的加权平均,权重由 pdata(z) 给出。学习大量条件路径即可间接学习整体分布的演化。
由于条件路径满足边界条件,边缘路径也满足 p0=pinit 且 p1=pdata。因此,只要找到驱动粒子沿 pt 演化的机制,就能从噪声生成数据。
高斯条件概率路径
常用的中间路径是高斯条件路径:
pt(x∣z)=N(x;αtz,βt2Id)
其中 αt 和 βt 是噪声调度函数,满足 α0=0,β0=1 和 α1=1,β1=0。该路径通过线性变换和噪声缩放,使分布从标准高斯逐渐收敛到 z。常见调度如下:
| 路径类型 |
αt |
βt |
几何特征 |
| 最优传输路径 |
t |
1−t |
严格直线演化,速度恒定 |
| 方差保持路径 |
1−σt2 |
σt |
曲线演化,沿球面移动 |
| 方差爆炸路径 |
1 |
σ(t) |
均值不变,仅方差扩张 |
调整 αt,βt 可得到不同几何路径。最优传输路径对应线性插值,轨迹直接、速度形式简单。
从条件路径采样可写为:
z∼pdataϵ∼pinit=N(0,Id)⟹x=αtz+βtϵ∼pt
向量场
条件向量场
概率路径给出分布如何变化;向量场给出粒子在该路径上的速度。
对每个数据点 z,定义 条件向量场 Conditional Vector Field:
X0∼pinitdtdXt=uttarget(Xt∣z)⟹Xt∼pt(⋅∣z)(0≤t≤1)
其中 uttarget(Xt∣z) 是目标条件向量场。
X0∼pinit 是噪声起点。给定初始点后,ODE 定义的流 ψt(x0) 确定粒子位置。向量场、ODE 和流分别对应速度规则、局部变化和全局轨迹。
连续性方程:向量场改变概率分布的基础是连续性方程,它描述概率质量在向量场下的守恒演化:
∂t∂pt(x)+div(ptut)(x)=0
其中 div(ptut) 是概率流散度,∂tpt(x) 是密度变化率。若向量场满足该方程,则概率质量只发生连续搬运,不凭空产生或消失。
对高斯条件路径 pt(x∣z)=N(x;αtz,βt2Id),可用流图 ψt(x0∣z)=αtz+βtx0 求条件向量场:
dtdψt(x0∣z)=α˙tz+β˙tx0=uttarget(ψt(x0∣z)∣z)
将 x0 替换为 (x−αtz)/βt,得到闭式解:
uttarget(x∣z)=(α˙t−βtβ˙tαt)z+βtβ˙tx
该速度由数据点 z 相关项和尺度变化项组成。对 CondOT 路径(αt=t,βt=1−t),可简化为 ut(x∣z)=z−ϵ,其中 ϵ 是初始噪声。
边缘向量场
条件向量场可由条件路径直接构造。对所有可能的 z 做后验加权平均,即得到边缘向量场:
uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz
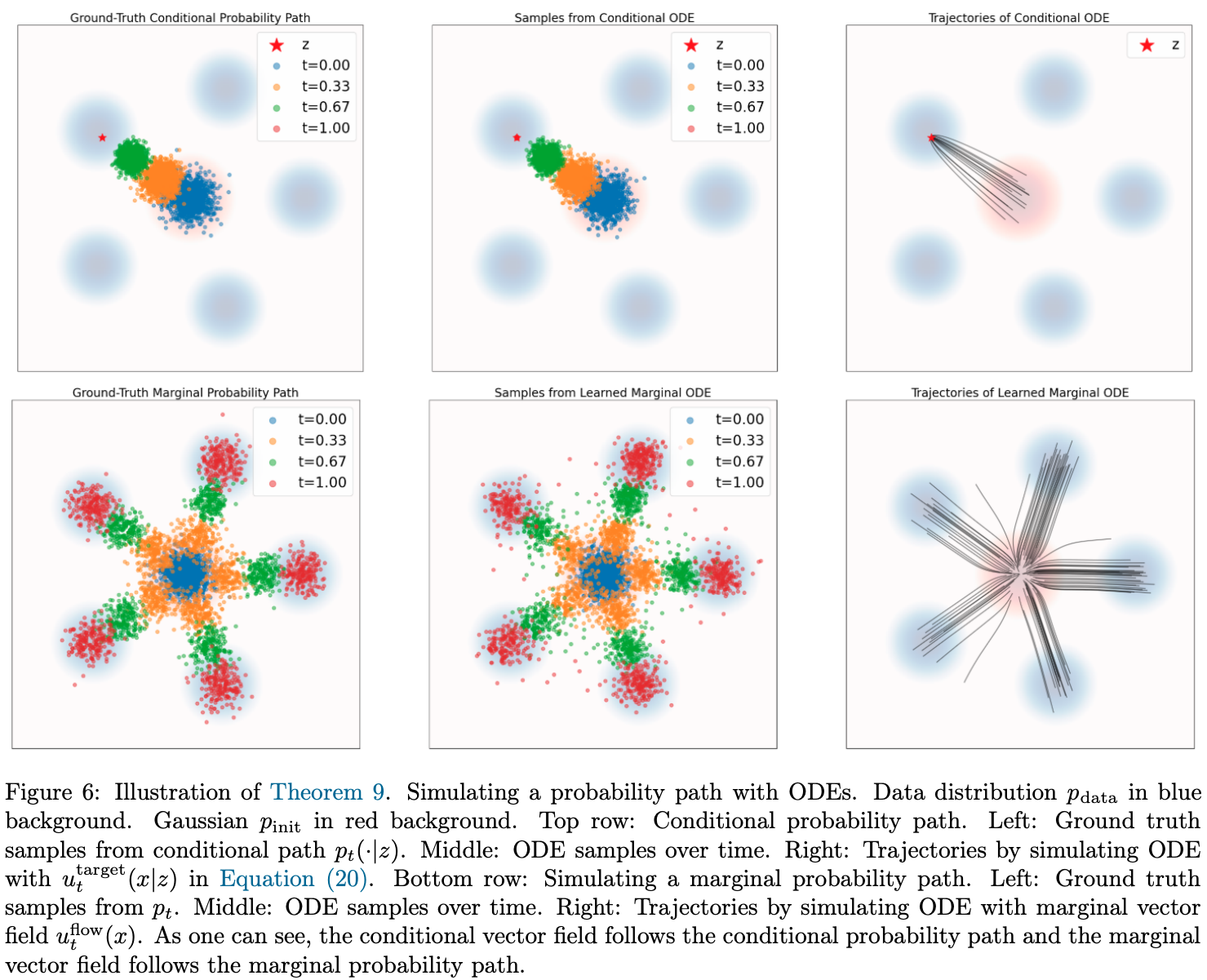
权重 pt(x)pt(x∣z)pdata(z) 是后验概率 pt(z∣x)。因此,位置 x 的边缘速度等于所有条件速度的后验期望:
uttarget(x)=Ez∼pdata(⋅∣x)[uttarget(x∣z)]
直观上,uttarget(x∣z) 表示“若终点是 z,当前位置应如何移动”,pt(z∣x) 表示当前位置最终对应各数据点的概率。二者加权积分得到当前位置的平均运动方向。
流匹配损失
定义概率路径和向量场后,目标是学习边缘向量场,即总体分布的演化速度。
理想的 流匹配损失 FM Loss 要求神经网络向量场 vθ(x,t) 逼近真实边缘向量场 uttarget(x):
LFM(θ)=Et∼Unif,x∼pt(x)[∥vθ(x,t)−uttarget(x)∥2]
但 uttarget(x) 依赖未知的 pdata,不能直接计算。因此使用可计算的 条件流匹配损失 CFM Loss:
LCFM(θ)=Et,z∼pdata,x∼pt(x∣z)[∥vθ(x,t)−uttarget(x∣z)∥2]
其中 uttarget(x∣z) 和 pt(x∣z) 可直接计算。可以证明 FM 与 CFM 对参数 θ 的梯度等价:
∇θLFM(θ)=∇θLCFM(θ)
因此,训练时匹配条件速度即可得到正确的边缘向量场。
FM/CFM 等价性证明
- 展开 FM 损失:
LFM(θ)=Et,x
其中第三项 ∥uttarget∥2 不含 θ,优化时可视为常数。
- 处理交叉项:利用边缘化公式 uttarget(x)=∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz。
Ex∼pt=∫pt(x)vθ(x,t)T(∫uttarget(x∣z)pt(x)pt(x∣z)pdata(z)dz)dx
⋯=∫∫vθ(x,t)Tuttarget(x∣z)pt(x∣z)pdata(z)dxdz
这等价于 Ez∼pdata,x∼pt(x∣z)。
- 合并回归目标:同理可证明第一项 ∥vθ∥2 的期望一致。因此两个损失关于 θ 的一阶导数一致。
确定损失后,训练流程如下:






