高维数据生成的局限
生成模型需要学习真实数据分布 pdata。以 1024×1024 RGB 图像为例,x∈Rd,其中 d=3×1024×1024≈3×106。若直接在像素空间训练扩散模型,网络需要在每个时间步处理百万级维度,计算和显存开销很高;视频还会因时间维度进一步放大状态空间。
现代生成架构引入 潜在空间 Latent Space,其依据是流形假设:高维数据虽然处于大维度像素空间,但实际集中在低内在维度流形附近。
因此可先用非线性压缩将数据投影到低维潜在空间,再在该空间中训练生成模型。自编码器,尤其是 变分自编码器 Variational Autoencoders,常用于构建这种潜在空间。
标准自编码器
确定性特征映射
标准自编码器由两个确定性神经网络组成:编码器负责压缩,解码器负责重构。
编码器 Encoder 定义为 μϕ:Rd→Rk,将输入 x∈Rd 压缩为潜在向量 z∈Rk,通常 k≪d。
解码器 Decoder 定义为 μθ:Rk→Rd,将潜在向量还原为重构数据 x^。
其中 ϕ,θ 分别是编码器和解码器参数。训练目标是最小化输入和重构结果之间的均方误差:
LRecon(ϕ,θ)=Ex∼pdata[∣∣μθ(μϕ(x))−x∣∣2]
离散隐空间的局限
标准自编码器可实现压缩和重构,但直接用于生成存在潜在空间结构问题。
原因是其损失只约束重构误差,没有显式约束潜在空间 Rk 的分布形状。编码结果可能离散、断裂,缺少连续结构。
潜在向量集合 {z1,z2,…,zN} 可能形成孤立点簇,点簇之间是未训练区域。随机采样或插值容易落入这些区域,解码器对流形外输入缺乏可靠泛化。
确定性自编码器只保证训练样本附近可解码,不能保证任意潜在点都对应合理数据。
变分自编码器
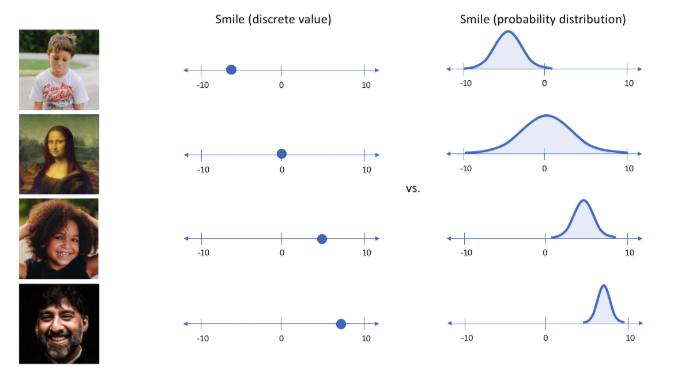
VAE 将编码器和解码器改为概率模型,使潜在空间更平滑、连续,并适合下游生成。
概率编码器与解码器
VAE 中,编码器是后验条件分布 qϕ(z∣x),解码器是条件生成分布 pθ(x∣z)。常用假设是二者为对角高斯:
qϕ(z∣x)=N(z;μϕ(x),diag(σϕ2(x)))
pθ(x∣z)=N(x;μθ(z),σθ2(z)Id)
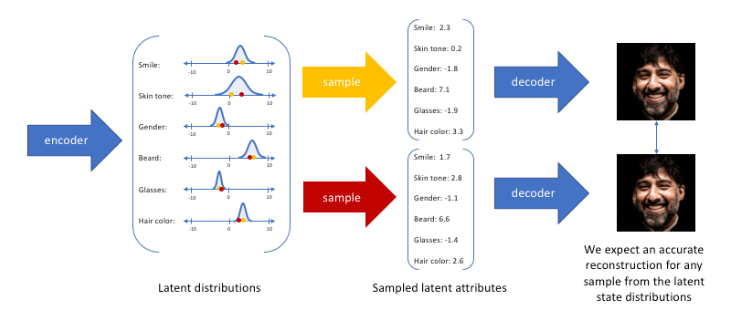
编码器不再输出单点,而是输出均值 μϕ(x) 和方差 σϕ2(x)(实践中常输出 logσϕ2(x))。因此,每个输入对应潜在空间中的高斯概率云。
解码器输出重构分布的均值 μθ(z) 和方差 σθ2(z)。自编码过程变为随机采样:
先采样潜在变量 z∼qϕ(⋅∣x),再采样重构数据 x∼pθ(⋅∣z)。
变分重构损失
引入概率机制后,重构目标改为最大化给定潜变量时真实数据的期望对数似然;取负值得到 VAE 重构损失:
LVAE−Recon(ϕ,θ)=−Ex∼pdata(x),z∼qϕ(⋅∣x)[logpθ(x∣z)]
该损失要求解码器对从 qϕ(⋅∣x) 中采样的潜变量都能高概率重构原始输入。
代入各向同性高斯密度:
N(x;μ,σ2I)=(2πσ2)−2dexp(−2σ2∣∣x−μ∣∣22)
取对数并忽略与优化无关的常数,得到:
LVAE−Recon(ϕ,θ)=Ex∼pdata(x),z∼qϕ(z∣x)[2σθ2(z)1∣∣x−μθ(z)∣∣2+2dlogσθ2(z)]+const
第一项是由方差缩放的 MSE,第二项惩罚预测方差。实际训练中常将解码方差固定为常数 σθ2(z)=σ2,避免学习高维方差带来的不稳定。
此时方差惩罚项成为常数,重构损失退化为:
LVAE−Recon(ϕ,θ)=Ex∼pdata(x),z∼qϕ(z∣x)[2σ21∣∣x−μθ(z)∣∣2]+const
固定方差后,VAE 重构损失与 MSE 等价,差异在于潜变量 z 来自概率采样而非确定性映射。
Kullback-Leibler 散度约束
仅使用重构损失时,编码器可令 σϕ2→0,退化为确定性自编码器,并重新产生潜在空间断裂。因此需要对编码器输出分布加入先验约束。
高斯先验分布
引入预设 先验分布 Prior Distribution pprior(z),作为潜在空间的目标分布。常用先验为标准各向同性高斯:
pprior(z)=N(0,Ik)
该先验易采样,且各维独立,有利于获得结构更规则的潜在表示。
KL 散度损失
先验确定后,需要使 qϕ(z∣x) 接近 N(0,Ik)。使用 KL 散度 衡量分布差异:
DKL(q(x)∣∣p(x))=∫q(x)logp(x)q(x)dx=EX∼q[logp(X)q(X)]
KL 散度满足非负性 DKL(q(x)∣∣p(x))≥0,且仅当 q=p 时取 0。VAE 将其作为先验损失:
LVAE−Prior(ϕ)=Ex∼pdata(x)
当后验和先验均为对角高斯时,KL 散度有闭式解。设 q(x)=N(x;μq,diag(σq2)),p(x)=N(x;μp,diag(σp2)),其对数密度为:
logq(x)=−21log(2πσq2)−2σq21∣∣x−μq∣∣2
logp(x)=−21log(2πσp2)−2σp21∣∣x−μp∣∣2
代入 DKL(q∣∣p)=Ex∼q[logq(x)−logp(x)]:
DKL(q∣∣p)=21logσq2σp2+2σp21Eq[∣∣x−μp∣∣2]−2σq21Eq[∣∣x−μq∣∣2]
利用 Eq[∣∣x−μq∣∣2]=σq2 与 Eq[∣∣x−μp∣∣2]=σq2+∣∣μq−μp∣∣2,得到:
DKL(q∣∣p)=21(K(σp2σq2)+σp2∣∣μq−μp∣∣2)
其中函数被定义为 K(α)=∑i=1k(αi−logαi−1)。
标准 VAE 中 μp=0,σp2=1,因此先验损失为:
LVAE−Prior(ϕ)=Ex∼pdata(x)[21K(σϕ2(x))+21∣∣μϕ(x)∣∣2]
该损失包含两类约束:
- 二次范数惩罚项 21∣∣μϕ(x)∣∣2:约束编码均值靠近原点。
- 函数项 21K(σϕ2(x)):约束方差接近 1,避免方差塌缩为 0,并促使潜在概率云适度重叠。
β-VAE 训练目标函数
将重构损失与先验损失相加,并引入 β≥0 控制权重,得到 β-VAE 目标:
LVAE(ϕ,θ)=LVAE−Recon(ϕ,θ)+βLVAE−Prior(ϕ)
=Ex∼pdata(x),z∼qϕ(z∣x)[2σθ2(z)1∣∣x−μθ(z)∣∣2+2dlogσθ2(z)+2βK(σϕ2(x))+2β∣∣μϕ(x)∣∣2]
| VAE 损失项组件 |
数学公式表达 |
核心驱动功能 |
| 均方重构误差 |
2σθ2(z)1∣x−μθ(z)∣2 |
约束重构图像的生成质量 |
| 解码不确定性 |
2dlogσθ2(z) |
控制重构约束强度。 |
| 方差收敛正则化 |
2βK(σϕ2(x)) |
防止方差塌缩,保持潜在空间连续性。 |
| 均值引力正则化 |
2β∣μϕ(x)∣2 |
约束编码均值接近 0。 |
重参数化
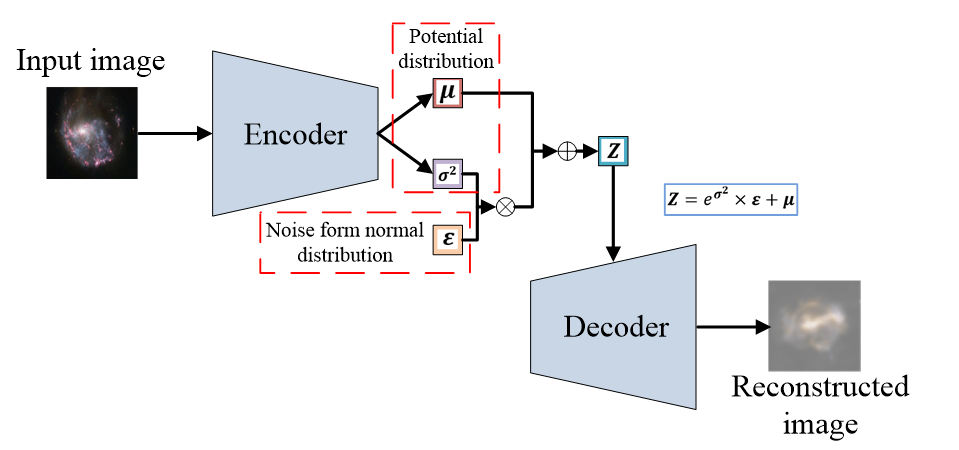
VAE 损失涉及 z∼qϕ(z∣x) 的随机采样。采样操作本身不可导,会阻断梯度传回编码器参数 ϕ。重参数化技巧用于解决该问题。
重参数化将随机性转移到独立噪声源。对 z∼N(μϕ(x),σϕ2(x)Ik),引入 ϵ∼N(0,Ik),可写为:
z=μϕ(x)+σϕ(x)⊙ϵ
其中 ⊙ 表示逐元素乘法。
这样计算图变为:
- 噪声 ϵ 与参数 ϕ 独立。
- z 由 μϕ(x)、σϕ(x) 和 ϵ 经可导运算得到。
- 梯度可通过加法和乘法传回 μϕ 与 σϕ。
重参数化后,期望从依赖参数的后验分布转为对独立噪声 ϵ 的期望:
LVAE(ϕ,θ)=Ex∼pdata(x),ϵ∼N(0,Ik)[2σθ2(z)1∣∣x−μθ(μϕ(x)+σϕ(x)ϵ)∣∣2+2dlogσθ2(z)+2βK(σϕ2(x))+2β∣∣μϕ(x)∣∣2]
固定解码方差为常数 σ2 后,可实现的损失为:
LVAE(ϕ,θ)=Ex∼pdata(x),ϵ∼N(0,Ik)[2σ21∣∣x−μθ(μϕ(x)+σϕ(x)ϵ)∣∣2+2βK(σϕ2(x))+2β∣∣μϕ(x)∣∣2]
重参数化也出现在 Gumbel-Softmax 和扩散模型采样式 xt=αtx0+1−αtϵ 中。
下表为标准 β-VAE 的单次迭代流程:
| 训练步骤 |
操作名称 |
具体的数学算子与张量流转逻辑 |
| 步骤 1 |
前向信息编码 |
输入 mini-batch {xi}i=1B,输出 μi←μϕ(xi) 和 logσi2←logσϕ2(xi)。 |
| 步骤 2 |
外部噪声采样 |
采样独立噪声 ϵi∼N(0,Ik)。 |
| 步骤 3 |
重参数化运算 |
计算 σi=exp(21logσi2),再得 zi←μi+σi⊙ϵi。 |
| 步骤 4 |
前向空间解码 |
输入 zi 到解码器,输出 x^i←μθ(zi)。 |
| 步骤 5 |
损失函数聚合 |
计算重构损失 Lrecon 与 KL 损失 LKL,聚合为 L←Lrecon+βLKL。 |
| 步骤 6 |
梯度回传更新 |
反向传播并更新 ϕ,θ。 |

工程稳定性补充:
- KL 预热:训练初期令 β 较小,先保证重构,再逐步增强先验约束。
- 为了提高训练稳定性,一些实现将解码器的方差输出固定为常数方差 σ,而不是由神经网络学习的方差 σθ。这种设置下重建项约束 2σθ2(z)1∥x−μθ(z)∥2 和均方误差 ∥x−μθ(z)∥2 成固定比例。
- 感知损失:用预训练网络的特征空间损失缓解 MSE 带来的过度平滑。
- GAN 对抗损失:增强高频纹理和边缘质量。
ELBO 与联合分布
全局 KL 散度极小化
VAE 同时包含 X→Z 与 Z→X 两条通道,对应两个关于数据 x 与潜变量 z 的联合分布:
- 由编码器诱导的联合分布:数据来自真实分布,再由编码器映射到潜层,定义为 qϕ(x,z)=pdata(x)qϕ(z∣x)。
- 由解码器诱导的联合分布:潜变量来自先验分布,再由解码器映射回数据空间,定义为 pθ(x,z)=pθ(x∣z)pprior(z)。
训练 VAE 的目标是选择参数 ϕ 和 θ,使编码路径与生成路径诱导的联合分布尽量一致,即最小化它们之间的全局 KL 散度:
DKL(qϕ(x,z)∣∣pθ(x,z))=Eqϕ[log(pθ(x∣z)pprior(z)pdata(x)qϕ(z∣x))]
展开对数项,并利用期望的线性性,可得:
=Ex∼pdata[logpdata(x)]+Ex∼pdata−Ex∼pdata,z∼qϕ[logpθ(x∣z)]
其中 E[logpdata(x)] 只由数据分布决定,与网络参数 ϕ,θ 无关,可视为常量。因此:
DKL(qϕ(x,z)∣∣pθ(x,z))=Const+LVAE(ϕ,θ)
因此,最小化 LVAE 等价于最小化编码器联合分布与解码器联合分布之间的全局散度。重构项与 KL 正则项并非经验拼接,而对应联合分布对齐。
证据下界
生成模型通常希望最大化真实样本的边缘对数似然 logpθ(x)。
但 pθ(x)=∫pθ(x∣z)pprior(z)dz 是高维连续积分,通常不可解析,也难以直接数值计算。
变分推断引入可训练分布 qϕ(z∣x) 作为真实后验 pθ(z∣x) 的近似。由贝叶斯公式 pθ(z∣x)=pθ(x)pθ(x∣z)pprior(z) 并整理散度项,可得:
Ez∼qϕ(z∣x)[log(qϕ(z∣x)pθ(x∣z)pprior(z))]+DKL(qϕ(z∣x)∣∣pθ(z∣x))=logpθ(x)
由于 DKL(qϕ(z∣x)∣∣pθ(z∣x))≥0,可得到边缘对数似然的下界:
logpθ(x)≥Ez∼qϕ(z∣x)[log(qϕ(z∣x)pθ(x∣z)pprior(z))]≡ELBO(x;ϕ,θ)
该下界称为 证据下界 Evidence Lower Bound。展开 ELBO 内部的对数项后,得到 Eqϕ[logpθ(x∣z)]−DKL(qϕ(z∣x)∣∣pprior(z)),即负的变分自编码器损失 −LVAE。
因此,最小化 LVAE 等价于最大化不可直接计算的边缘似然 logpθ(x) 的下界 ELBO。
“变分”的含义:真实后验 pθ(z∣x) 的分母包含不可解积分 logpθ(x),无法直接计算。因此引入可控、可训练的分布族 qϕ(⋅∣x) 近似真实后验,并通过优化缩小二者差距。
扩散模型中的 VAE
训练好的 VAE 可以独立生成:推理时采样 z∼pprior 并输入解码器即可得到样本。现代潜在扩散仍在 VAE 的潜在空间中建模,原因在于 VAE 单独作为生成器存在摊销差距,而扩散模型更适合学习复杂潜在分布。
VAE 生成任务的瓶颈
当 VAE 独立承担完整生成任务时,生成质量受摊销差距限制。由 ELBO 分解有:
logpθ(x)=ELBO+DKL(qϕ(z∣x)∥pθ(z∣x))
边缘对数似然与 ELBO 的差距由变分近似 qϕ(z∣x) 和真实后验 pθ(z∣x) 的差异决定。
从聚合潜在分布视角,可由信息处理不等式得到:
DKL(qϕ(x,z)∥pθ(x,z))≥DKL(qϕ(z)∥pprior(z))
该式说明,只要联合分布没有完全对齐,聚合潜在分布 qϕ(z)=∫qϕ(z∣x)pdata(x)dx 与标准高斯先验 pprior(z) 之间仍可能存在差异。
推理时若直接从 pprior(z) 采样并输入解码器,解码器会接收与训练阶段 qϕ(z) 不一致的输入,产生分布外偏移。该失配与 MSE 重构损失的均值化倾向共同导致单独 VAE 生成图像常见的边缘模糊和高频细节缺失,即“VAE 特征性模糊”。
建模潜在分布
潜在扩散模型 Latent Diffusion Models 将 VAE 定位为感知压缩器,将扩散模型定位为潜在分布建模器。
在该范式中,VAE 主要负责把高维像素空间压缩为低维潜在空间,不再要求潜在流形完全匹配标准高斯。语义结构生成与跨模态对齐由潜在空间内的扩散模型完成。扩散模型可通过连续扩散的分数匹配或流匹配拟合向量场,学习从标准高斯到聚合潜在分布 qϕ(z) 的反向过程。
这种分工带来两点优势:
-
扩散模型避免直接在高维像素空间建模,将计算集中在低维潜在空间中的语义生成。
-
VAE 聚焦压缩与重构质量,负责把扩散模型生成的 z 解码为图像。实践上,基于 SDEs 和 ODEs 的扩散过程在匹配复杂非平稳分布时通常比单次前馈 VAE 更灵活,因此潜在扩散成为高质量生成模型的常用架构。
| 架构策略范式对比 |
所处运算空间 |
核心优势 |
主要瓶颈 |
在当前生态中的演进定位 |
| 全尺寸像素级扩散 |
原始数据域 RH×W×3 |
无解码器介入,不存在压缩损失,逼真度上限高。 |
推理时间与显存占用随分辨率快速增长,难以扩展到千万像素或长视频。 |
主要用于理论验证或低分辨率图像生成试验(如早期 DDPM)。 |
| 单一 VAE 前馈生成 |
低维潜在流形 Rk |
采样速度快,一次编码与一次解码即可出图。 |
受摊销差距限制,图像易出现特征性模糊,难以灵活接入复杂外部条件(如文本)。 |
更适合实时编解码、异常检测等对速度要求高的任务。 |
| 组合式潜在扩散 |
极低维语义流形 Rk |
在高分辨率生成与算力限制之间取得较好平衡,适合多模态高质量对齐。 |
生成上限受 VAE 第一阶段预训练压缩损失限制,可能存在细节重构误差。 |
当前高质量生成模型的主流架构之一,如 Stable Diffusion 3、Meta Movie Gen。 |





